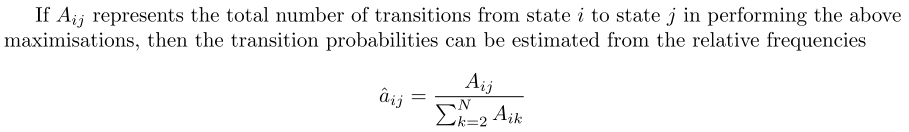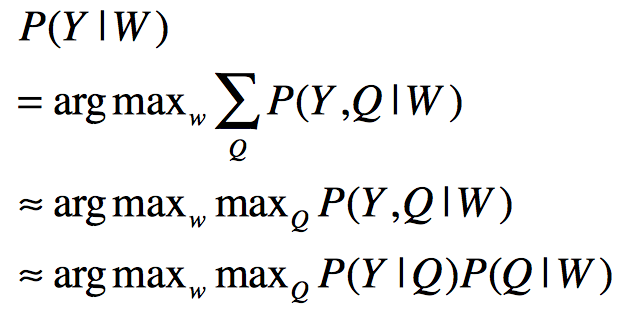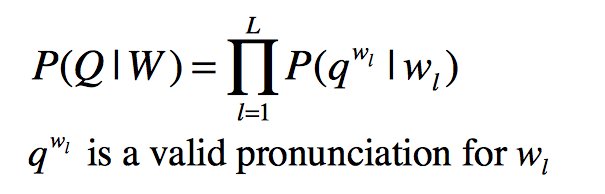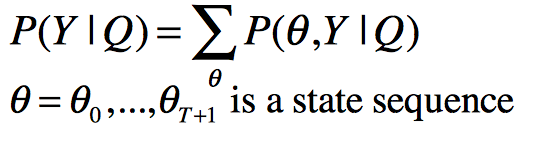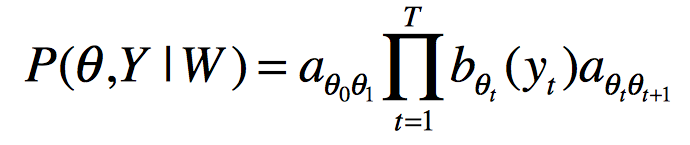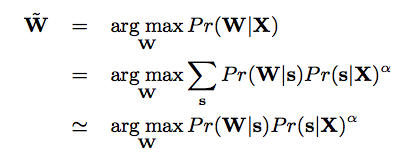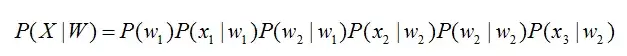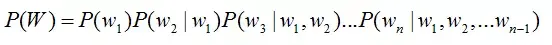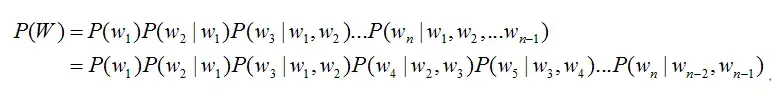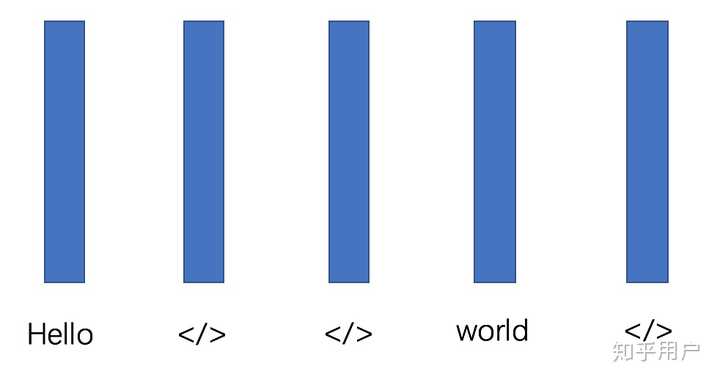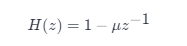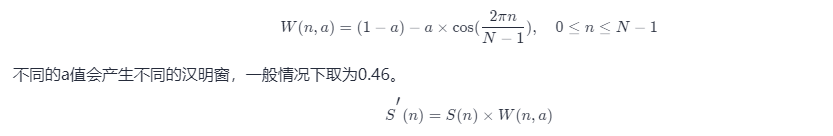本题已收录至知乎圆桌:人工智能 · 语言智能,更多「人工智能」相关话题欢迎关注讨论
简要给大家介绍一下语音怎么变文字的吧。需要说明的是,这篇文章为了易读性而牺牲了严谨性,因此文中的很多表述实际上是不准确的。对于有兴趣深入了解的同学,本文的末尾推荐了几份进阶阅读材料。下面我们开始。 首先,我们知道声音实际上是一种波。常见的mp3等格式都是压缩格式,必须转成非压缩的纯波形文件来处理,比如Windows PCM文件,也就是俗称的wav文件。wav文件里存储的除了一个文件头以外,就是声音波形的一个个点了。下图是一个波形的示例。
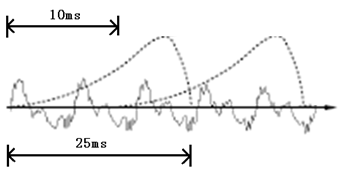
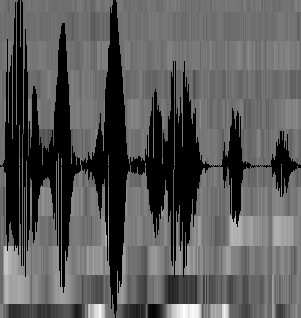
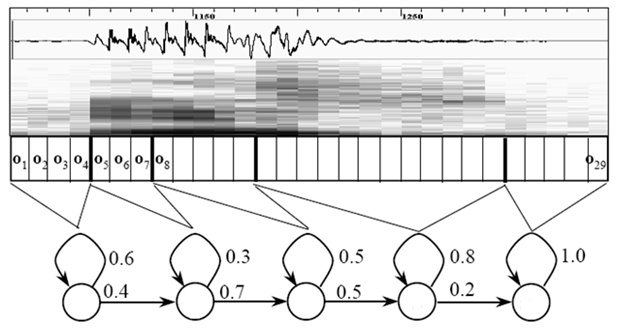
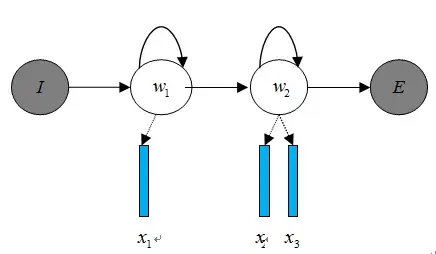
在开始语音识别之前,有时需要把首尾端的静音切除,降低对后续步骤造成的干扰。这个静音切除的操作一般称为VAD,需要用到信号处理的一些技术。 要对声音进行分析,需要对声音分帧,也就是把声音切开成一小段一小段,每小段称为一帧。分帧操作一般不是简单的切开,而是使用移动窗函数来实现,这里不详述。帧与帧之间一般是有交叠的,就像下图这样: 图中,每帧的长度为25毫秒,每两帧之间有25-10=15毫秒的交叠。我们称为以帧长25ms、帧移10ms分帧。 分帧后,语音就变成了很多小段。但波形在时域上几乎没有描述能力,因此必须将波形作变换。常见的一种变换方法是提取MFCC特征,根据人耳的生理特性,把每一帧波形变成一个多维向量,可以简单地理解为这个向量包含了这帧语音的内容信息。这个过程叫做声学特征提取。实际应用中,这一步有很多细节,声学特征也不止有MFCC这一种,具体这里不讲。 至此,声音就成了一个12行(假设声学特征是12维)、N列的一个矩阵,称之为观察序列,这里N为总帧数。观察序列如下图所示,图中,每一帧都用一个12维的向量表示,色块的颜色深浅表示向量值的大小。
接下来就要介绍怎样把这个矩阵变成文本了。首先要介绍两个概念: - 音素:单词的发音由音素构成。对英语,一种常用的音素集是卡内基梅隆大学的一套由39个音素构成的音素集,参见The CMU Pronouncing Dictionary。汉语一般直接用全部声母和韵母作为音素集,另外汉语识别还分有调无调,不详述。
- 状态:这里理解成比音素更细致的语音单位就行啦。通常把一个音素划分成3个状态。
语音识别是怎么工作的呢?实际上一点都不神秘,无非是:
把帧识别成状态(难点)。
把状态组合成音素。
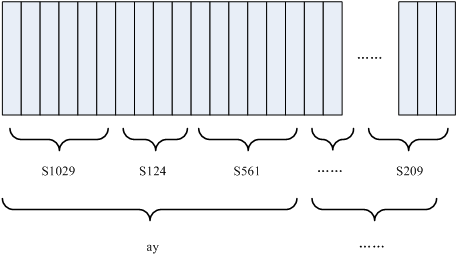
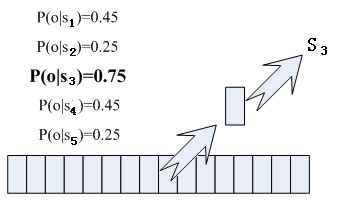
把音素组合成单词。 如下图所示: 图中,每个小竖条代表一帧,若干帧语音对应一个状态,每三个状态组合成一个音素,若干个音素组合成一个单词。也就是说,只要知道每帧语音对应哪个状态了,语音识别的结果也就出来了。 那每帧音素对应哪个状态呢?有个容易想到的办法,看某帧对应哪个状态的概率最大,那这帧就属于哪个状态。比如下面的示意图,这帧在状态S3上的条件概率最大,因此就猜这帧属于状态S3。
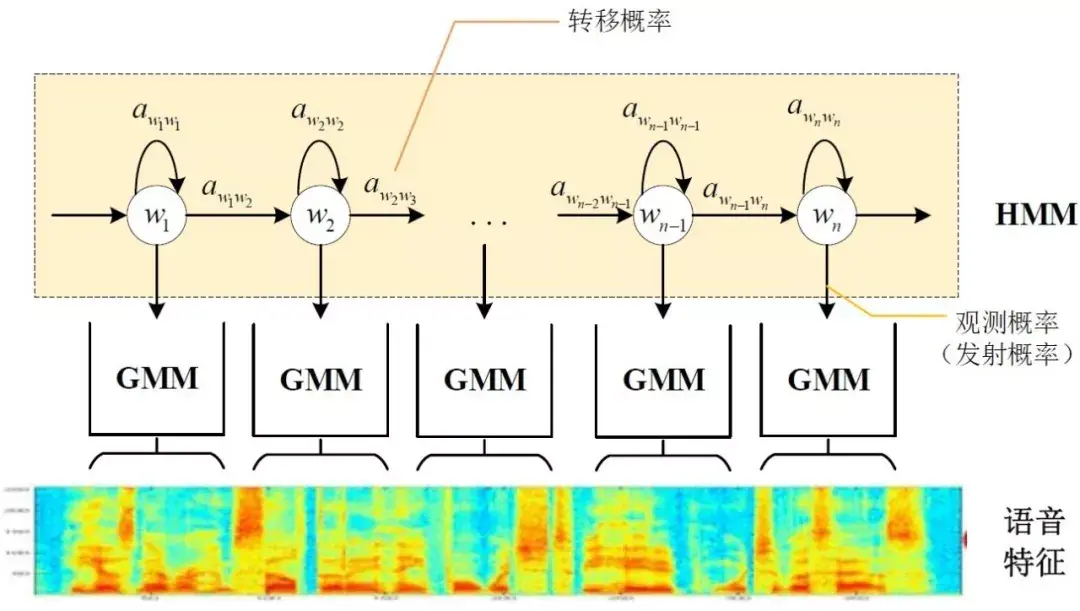
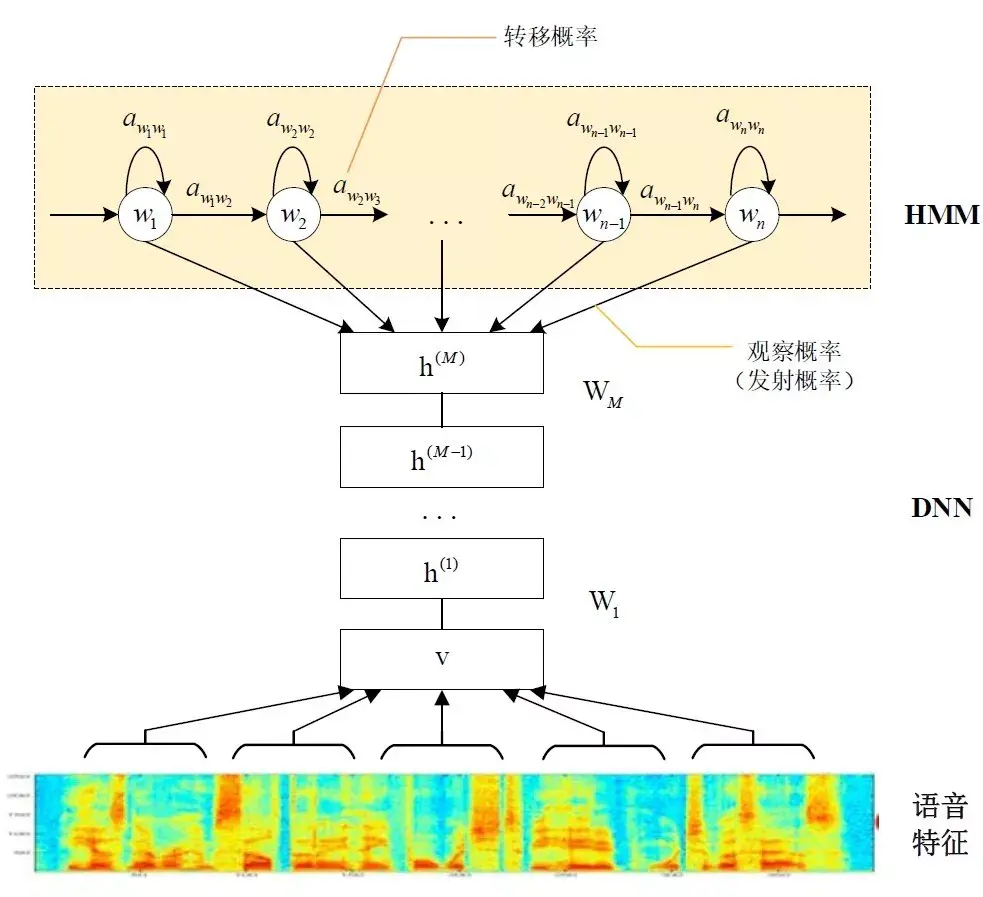
那这些用到的概率从哪里读取呢?有个叫“声学模型”的东西,里面存了一大堆参数,通过这些参数,就可以知道帧和状态对应的概率。获取这一大堆参数的方法叫做“训练”,需要使用巨大数量的语音数据,训练的方法比较繁琐,这里不讲。 但这样做有一个问题:每一帧都会得到一个状态号,最后整个语音就会得到一堆乱七八糟的状态号。假设语音有1000帧,每帧对应1个状态,每3个状态组合成一个音素,那么大概会组合成300个音素,但这段语音其实根本没有这么多音素。如果真这么做,得到的状态号可能根本无法组合成音素。实际上,相邻帧的状态应该大多数都是相同的才合理,因为每帧很短。 解决这个问题的常用方法就是使用隐马尔可夫模型(Hidden Markov Model,HMM)。这东西听起来好像很高深的样子,实际上用起来很简单:
第一步,构建一个状态网络。
第二步,从状态网络中寻找与声音最匹配的路径。 这样就把结果限制在预先设定的网络中,避免了刚才说到的问题,当然也带来一个局限,比如你设定的网络里只包含了“今天晴天”和“今天下雨”两个句子的状态路径,那么不管说些什么,识别出的结果必然是这两个句子中的一句。 那如果想识别任意文本呢?把这个网络搭得足够大,包含任意文本的路径就可以了。但这个网络越大,想要达到比较好的识别准确率就越难。所以要根据实际任务的需求,合理选择网络大小和结构。 搭建状态网络,是由单词级网络展开成音素网络,再展开成状态网络。语音识别过程其实就是在状态网络中搜索一条最佳路径,语音对应这条路径的概率最大,这称之为“解码”。路径搜索的算法是一种动态规划剪枝的算法,称之为Viterbi算法,用于寻找全局最优路径。
这里所说的累积概率,由三部分构成,分别是: - 观察概率:每帧和每个状态对应的概率
- 转移概率:每个状态转移到自身或转移到下个状态的概率
- 语言概率:根据语言统计规律得到的概率
其中,前两种概率从声学模型中获取,最后一种概率从语言模型中获取。语言模型是使用大量的文本训练出来的,可以利用某门语言本身的统计规律来帮助提升识别正确率。语言模型很重要,如果不使用语言模型,当状态网络较大时,识别出的结果基本是一团乱麻。
这样基本上语音识别过程就完成了。
以上的文字只是想让大家容易理解,并不追求严谨。事实上,HMM的内涵绝不是上面所说的“无非是个状态网络”,如果希望深入了解,下面给出了一些阅读材料: Rabiner L R. A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE, 1989, 77(2): 257-286. 入门必读。深入浅出地介绍了基于HMM的语音识别的原理,不注重公式的细节推导而是着重阐述公式背后的物理意义。
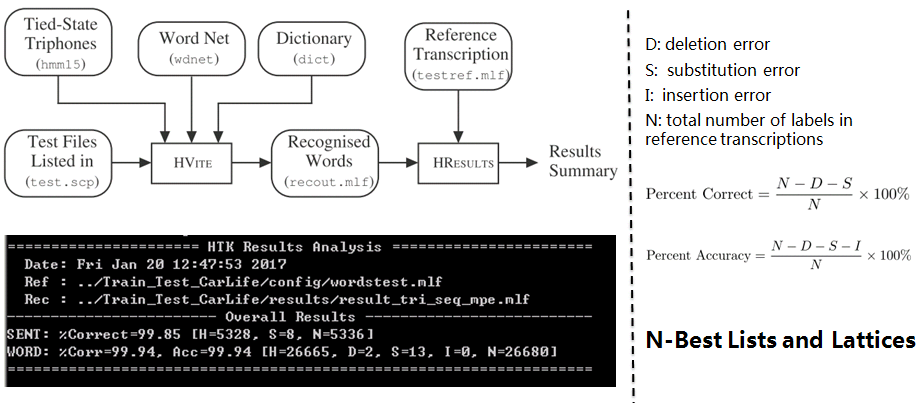
Bilmes J A. A gentle tutorial of the EM algorithm and its application to parameter estimation for Gaussian mixture and hidden Markov models. International Computer Science Institute, 1998, 4(510): 126. 详细介绍了用E-M算法训练HMM参数的推导过程,首先讲E-M的基本原理,然后讲解如何应用到GMM的训练,最后讲解如何应用到HMM的训练。
Young S, Evermann G, Gales M, et al. The HTK book (v3.4). Cambridge University, 2006. HTK Book,开源工具包HTK的文档。虽然现在HTK已经不是最流行的了,但仍然强烈推荐按照书里的第二章流程做一遍,你可以搭建出一个简单的数字串识别系统。
Graves A. Supervised Sequence Labelling with Recurrent Neural Networks. Springer Berlin Heidelberg, 2012: 15-35. 基于神经网络的语音识别的入门必读。从神经网络的基本结构、BP算法等介绍到 LSTM、CTC。
俞栋, 邓力. 解析深度学习——语音识别实践, 电子工业出版社, 2016. 高质量的中文书籍非常稀有,推荐买一本。最早把深度学习技术应用于语音识别就是这本书的作者。
当然,还有这本: 广告:《Kaldi 语音识别实战》
楼上张俊博的回答比较仔细的讲解了基础的经典语音识别算法。我想对算法背后的含义做一个简单的解释,对涉及到的特征提取(包括分帧)、音素建模、字典、隐式马尔科夫模型等可以参阅楼上的回答。 语音识别的第一个特点是要识别的语音的内容(比声韵母等)是不定长时序,也就是说,在识别以前你不可能知道当前的 声韵母有多长,这样在构建统计模型输入语音特征的时候无法简单判定到底该输入0.0到0.5秒还是0.2到0.8秒进行识别,同时多数常见的模型都不方便处理维度不确定的输入特征(注意在一次处理的时候,时间长度转化成了当前的特征维度)。一种简单的解决思路是对语音进行分帧,每一帧占有比较短固定的时 长(比如25ms),再假设说这样的一帧既足够长(可以蕴含 足以判断它属于哪个声韵母的信息),又很平稳(方便进行短时傅里叶分析),这样将每一帧转换为一个特征向量,(依次)分别识别它们属于哪个声韵母,就可以 解决问题。识别的结果可以是比如第100到第105帧是声母c,而第106帧到115帧是韵母eng等。 这种思路有点类似微积分 中的『以直代曲』。另外在实际的分帧过程中,还有很多常用技巧,比如相邻两帧之间有所重叠,或引入与临近帧之间的差分作为额外特征,乃至直接堆叠许多语音帧等等,这些都可以让前述的两个假设更可靠。近年来,研究种也出现了一些更新颖的处理方式,比如用.wav文件的采样点取代分帧并处理后的语音帧,但这样的方法在处理速度及性能上 暂时还没有优势。 当我们有了分帧后的语音特征之后,下一步常用的处理是使用某种分类器将之分类成某种跟语音内容相关的类别,如声韵母,这一步通常称作声学模型建模。对于分类目标的选取,最简单的选择可以是词组,或者是组成词组的汉字所对应的音节。但这样的选择方式通常会对训练模型的语音数据提出过高的要求,带来『数据稀疏』的问题,即数据中 很难包含汉语中的所有词组,同时每个词组也很难具有充足的训练样本以保证统计声学模型的可靠性。由于一个词组通常由多个音素的连续发音 构成,常见的音素都包含在国际音标表中,它们具有恰当的数目(通常几十个),以及清晰的定义(由特定的发声器官运动产生),于是音素成了各种语言中的语音识别中都最为常见的 建模选择(汉语的声韵母也是由一到三个音素构成), 识别中再结合词组到音素的发音字典使用。使用音素也方便对混合语言(如汉语种夹杂英语词汇)进行识别——当然不同母语的人对相同音素的发音也有区别,这是另外一个话题。另外由于人类发生器官运动的连续性,以及某些语言中特定的拼读习惯(比如英语中定冠词『the』在元音和辅音之前有不同读音),会导致发音,尤其是音素的发音受到前后音素的影响,称为『协同发音』。于是 可以进行所谓『上下文相关』的音素(或者考虑到音素实际的拼读,称为音子)分类。比如wo chi le这个序列,可以写为w o ch i l e,这样是普通的『上下文无关』音子序列,也可以考虑前一个音素对当前音素的影响写成sil-w w-o o-ch ch-i i-l l-e (sil表示语音开始前的静音,A-B表示收到A影响的B)或考虑后一个音素的影响写成w+o o+ch ch+i i+l l+e e+sil(sil表示语音结束后的静音,A+B表示受到B影响的A)。实际中以同时考虑前后各一个音素的三音子最为常见,最多也有人使用四音子模型。使用三音子或四音子模型会导致 分类目标的几何增长(如仅仅30个音素就可以扩展出30^3=27000个三音子), 并再次导致数据稀疏的问题。最常用的解决方法是使用基于决策树的方式对这些三音子或四音子模型进行聚类,对每一类模型进行参数共享以及训练数据的共享。在构建决策树的方式上以及决策树进行自顶向下的 分裂过程中,都可以 导入适当的语音学知识, 将知识与数据驱动的方法进行结合, 同时还可以 减少运算量并在识别中 使用训练数据中未出现的三音子模型等。 有了具体的分类的目标(比如三音子)之后,下面就要选择具体的数学模型进行声学建模。这里可以根据语音学等研究 使用多种线性结构或非线性结构的模型或模型组合。目前最广泛使用的仍然是基于隐式马尔科夫模型的建模方法,即对每个三音子分别建立一个模型,具体可以参见楼上的回答。隐式马尔科夫模型的转移概率密度以几何分布最为常见,但语音合成中也常用高斯分布;观测概率密度函数传统上通常使用 高斯混合模型,也有人使用人工神经网络等,近年来随着深度学习的发展,使用各种深层神经网络的情况 越来越多。最近也有人使用不同方法直接利用递归神经网络进行建模,有一些工作也取得了比较好的效果。但无论使用哪种模型甚至非线性的模型 组合,背后的含义都是假设了对应于每种 类别(三音子)的语音帧在它所对应的高维空间中具有几乎确定的空间分布,可以通过对空间进行划分,并由未知语音帧的空间位置来对语音帧进行正确的分类。 在完成声学模型建模后,就可以基于声学模型对未知语音帧序列进行语音识别了,这一过程通常称为搜索解码过程。解码的原理通常是在给定了根据语法、字典对马尔科夫模型进行连接后的搜索的网络(网络的每个节点可以是一个词组等)后,在所有可能的搜索路径中选择一条或多条最优(通常是最大后验概率)路径(字典中出现词组的词组串)作为识别结果,具体的搜索算法可以有不同的实现方式。这样的搜索可以对时序的语音帧根据其前后帧进行约束;注意使用多状态 隐式马尔科夫模型的理由之一是可以在 搜索中对每个三音子的最短长度施加限制。语音识别任务通常有不同的分类,最困难的问题是所谓大词表连续语音识别,即对可能由数万种日常用词组成的发音自然的语句(比如我们日常随意对话中的语句)进行识别,这样的 问题中通常要 将声学模型同概率语言模型联合使用,即在搜索中导入 统计获得的先验语言层级信息,优点是可以显著的提高识别器的性能,缺点是也会造成识别器明显偏向于识别出语言模型中 出现过的信息。 以上就是我理解的语音识别的原理,包括大致的系统构成和基本设计思路。具体在最前沿的研究和评测 中,通常还需要把许多不同的语音识别器通过各种不同的手段进行系统组合,以便在最终使最终的(组合)系统 能够获得具有互补性的信息,从而得到最佳的识别效果。
作者:九五要当学霸 链接: 知乎专栏来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。 原文:Adam Geitgey
翻译:巡洋舰科技——赵95
你是不是看烦了各种各样对于深度学习的报导,却不知其所云?我们要来改变这个问题。
有趣的机器学习 前五章已更新!点此查看第一章:最简明入门指南、第二章:用机器学习【制造超级马里奥】的关卡、第三章:图像识别【鸟or飞机】第四章:用深度进行【人脸识别】第五章:使用深度学习进行【语言翻译】和 序列的魔力第六章:如何用深度学习进行【语音识别】
语音识别正在“入侵”我们的生活。它内置在我们的手机,游戏主机和智能手表里。它甚至在自动化我们的家园。只需50美元,你可以买到一个Amazon Echo Dot -一个能够让你订购比萨,获知天气预报,甚至购买垃圾袋的魔术盒——只要你大声说出你的需求:
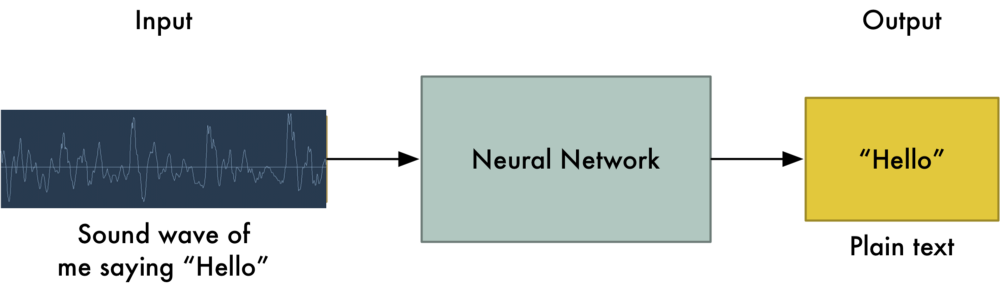
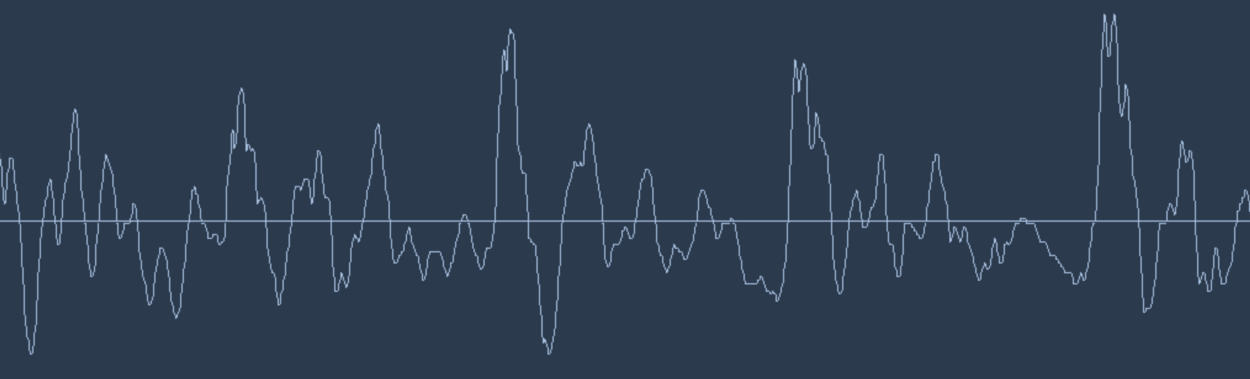
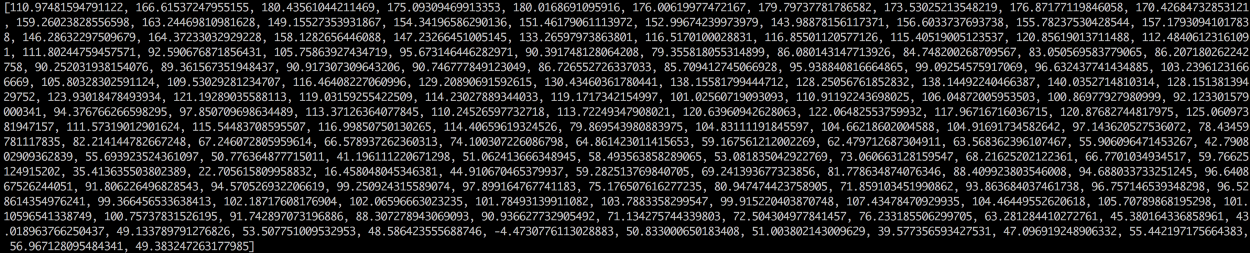
Alexa,订一个大号的比萨! Echo Dot机器人在(2016年圣诞)这个假期太受欢迎了,以至于Amazon似乎都没货了! 然而语音识别已经出现了几十年了,为何它才刚刚成为主流呢?原因是,深度学习,终于让语音识别,能够在非严格可控的环境下也能准确的识别。 吴恩达教授(百度首席科学家,人工智能和机器学习领域国际上最权威的学者之一,也是在线教育平台Coursera的联合创始人)长期以来预测,随着语音识别从95%精确度上升到99%,它将成为我们与计算机交互的主要方式。这个想法是基于,4%的精确度实际就是“太不靠谱”与“极度实用”之间的差别。感谢深度学习,我们终于达到了顶峰。 让我们了解一下如何用深度学习进行语音识别吧! 机器学习并不总是一个黑盒 如果你知道神经机器翻译是如何工作的,那么你可能会猜到,我们可以简单地将声音送入到神经网络中,并训练使之生成文本: 这就是用深度学习进行语音识别的核心,但目前我们还没有完全做到(至少在我写这篇文章的时候没做到——我打赌,在未来的几年我们可以做到)。 最大的问题是言速不同。一个人可能很快的说“hello!”而另一个人可能会非常缓慢说“heeeelllllllllllllooooo!”。这产生了一个更长的声音文件和更多的数据。这两个声音文件都应该被识别为完全相同的文本“hello!”而事实证明,把各种长度的音频文件自动对齐到一个固定长度的文本是很难的一件事情。 为了解决这个问题,我们必须使用一些特殊的技巧和一些除了深度神经网络以外的特殊处理。让我们看看它是如何工作的吧! 将声音转换成“位(Bit)” 语音识别的第一步是很显而易见的——我们需要将声波输入到计算机当中。 在第3章中,我们学习了如何把图像视为一个数字序列,以便我们直接将其输入进神经网络进行图像识别: 图像只是图片中每个像素深度的数字编码序列 但声音是作为波(Waves) 的形式传播的。我们如何将声波转换成数字呢?让我们使用我说的“hello”这个声音片段我们例子: 我说“hello”的波形 声波是一维的。(译者注:其实是二维的,有时间,还有振幅)在每个时刻,基于波的高度,它们有一个值(译者注:叫做振幅)。让我们把声波的一小部分放大看看: 为了将这个声波转换成数字,我们只记录声波在等距点的高度: 给声波采样 这被称为采样Sampling。我们每秒读取数千次,并把声波在该时间点的高度用一个数字记录下来。这基本上就是一个未压缩的.wav音频文件。 “CD音质”的音频是以44.1khz(每秒44,100个读数)进行采样的。但对于语音识别,16khz(每秒16,000个采样)的采样率足以覆盖人类语音的频率范围。 让我们把“Hello”的声波每秒采样16,000次。这是前100个采样: 每个数字表示在一秒钟的16000分之一处的声波的振幅 数字采样小助手 你可能认为采样只是对原始声波进行粗略近似估计,因为它只是间歇性的读取。我们的读数之间有间距,所以我们会丢失数据,对吗? 数字采样能否完美重现原始声波?那些间距怎么办? 但是,由于采样定理(Nyquist theorem),我们知道我们可以利用数学,从间隔的采样中完美的重建原始模拟声波——只要以我们希望得到的最高频率的两倍来采样就可以。 我提到这一点,是因为几乎每个人都会犯这个错误,并误认为使用更高的采样率总是能获得更好的音频质量。其实并不是。 预处理我们的采样声音数据 我们现在有一个数列,其中每个数字代表16000分之一秒的声波振幅。 我们可以把这些数字输入到神经网络中,但是试图直接分析这些采样来进行语音识别仍旧是困难的。相反,我们可以通过对音频数据进行一些预处理来使问题变得更容易。 让我们开始吧,首先将我们的采样音频分组为20毫秒长的块儿。这是我们第一个20毫秒的音频(即我们的前320个采样):
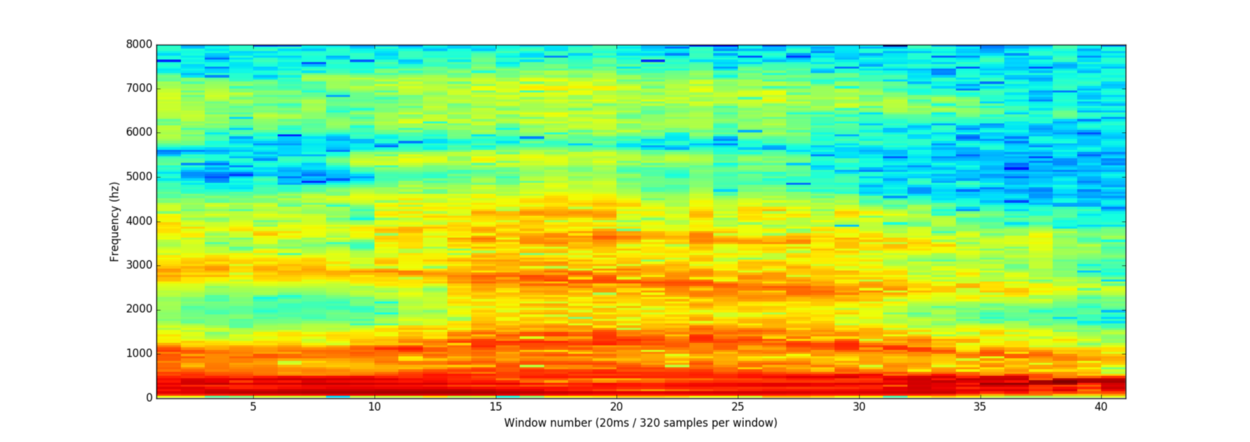
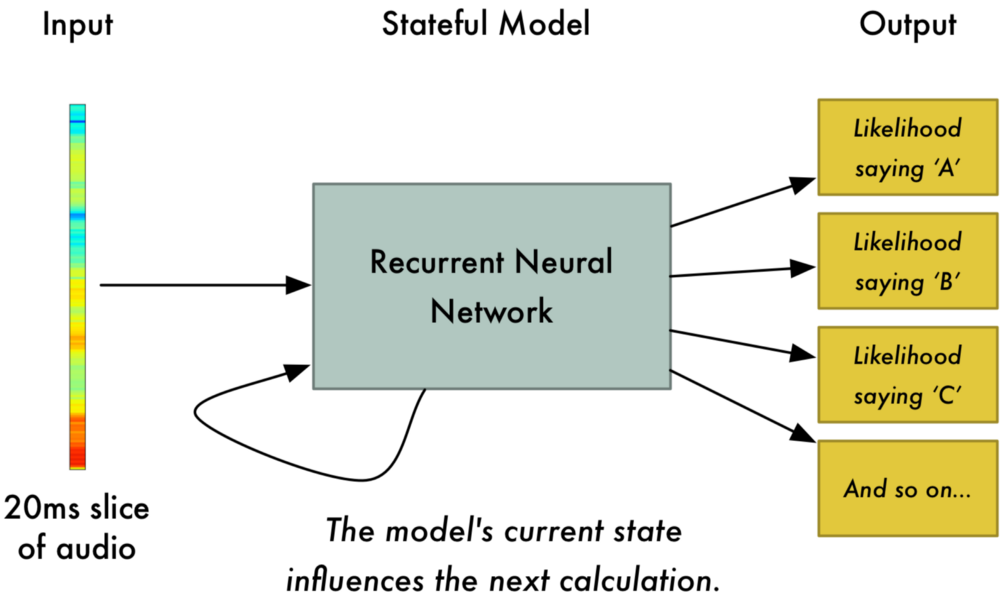
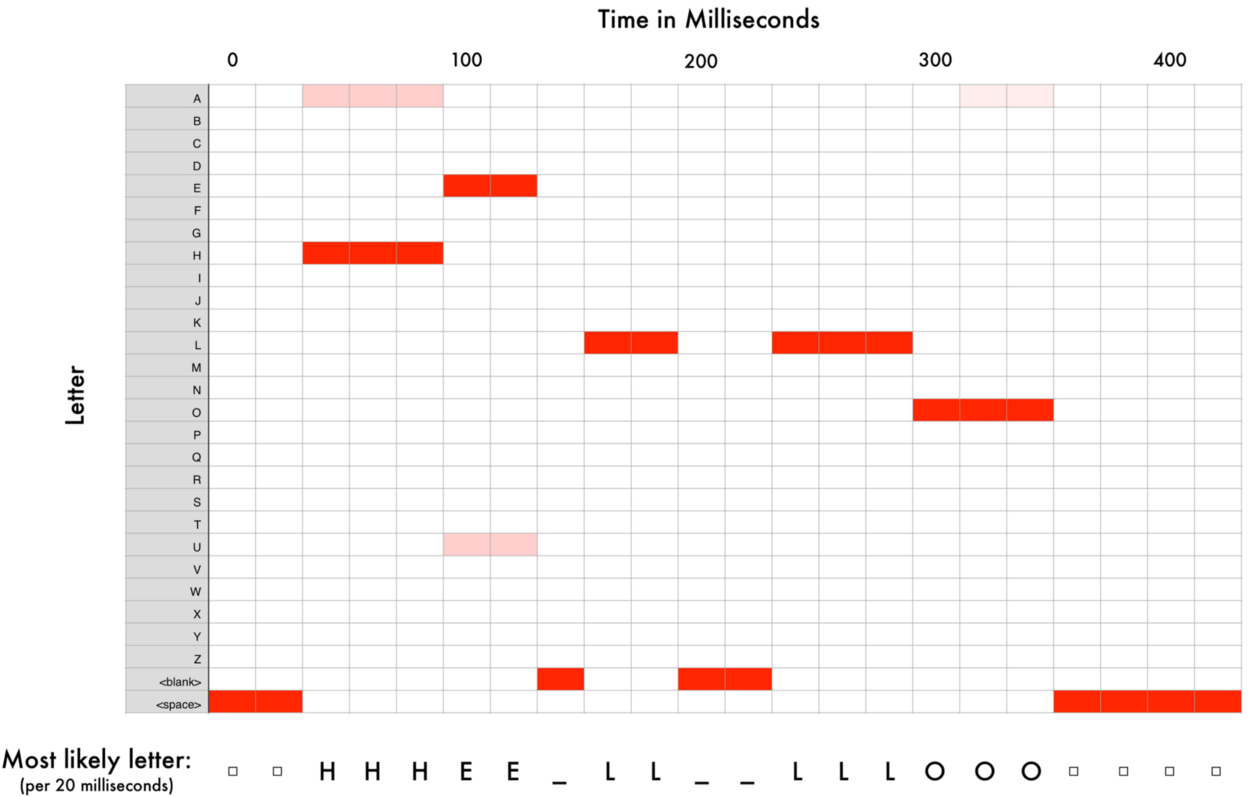
将这些数字绘制为简单折线图,图中给出了20毫秒时间内原始声波的粗略估计: 虽然这段录音只有50分之一秒的长度,但即使这样短暂的时长也是由不同频率的声音复杂的组合在一起的。一些低音,中音,甚至高音混在一起。但总的来说,就是这些不同频率的声音混合在一起,才组成了人类的语音。 为了使这个数据更容易被神经网络处理,我们将把这个复杂的声波分解成一个个组件部分。我们将一步步分离低音部分,下一个最低音部分,以此类推。然后通过将(从低到高)每个频带中的能量相加,我们就为各个类别(音调)的音频片段创建了一个指纹fingerprint。 想象你有一段某人在钢琴上演奏C大调和弦的录音。这个声音是由三个音符组合而成的 - C,E和G – 他们都混合在一起组成一个复杂的声音。我们想把这个复杂的声音分解成单独的音符,以此来发现它们是C,E和G。这和我们(语音识别)的想法一样。 我们使用被称为傅里叶变换Fourier Transform的数学运算来做到这一点。它将复杂的声波分解为简单的声波。一旦我们有了这些单独的声波,我们将每一个包含的能量加在一起。 最终结果是每个频率范围的重要程度,从低音(即低音音符)到高音。下面的每个数字表示我们的20毫秒音频剪辑中每个50Hz频带中有多少能量: 列表中的每个数字表示在50Hz频带中有多少能量 但是当你绘制一个图表时,你很容易看到这些能量: 你可以看到,我们的20毫秒声音片段中有很多低频率能量,然而在更高的频率中并没有太多的能量。这是典型“男性”的声音。 如果我们对每20毫秒的音频块重复这个过程,我们最终会得到一个频谱图(每一列从左到右都是一个20ms的块): “hello”声音剪辑的完整谱图 频谱图很酷,因为你可以从音频数据中实际看到音符和其他音高模式。对于神经网络来说,相比于原始声波,它可以更加容易地从这种数据中找到规律。因此,这就是我们将实际输入到神经网络的数据表示方式。 从短声音识别字符 现在我们有了一个易于处理的格式的音频,我们将把它输入到深度神经网络中去。神经网络的输入将会是20毫秒的音频块。对于每个小的音频切片(Audio Slice),它将试图找出当前正在说的声音对应的字母(letter)。 我们将使用一个循环神经网络 - 即一个拥有记忆来影响未来预测的神经网络。这是因为它预测的每个字母都应该能够影响下一个字母的预测可能性。例如,如果我们到目前为止已经说了“HEL”,那么很有可能我们接下来会说“LO”来完成“Hello”。我们不太可能会说“XYZ”之类根本读不出来的东西。因此,具有先前预测的记忆有助于神经网络对未来进行更准确的预测。 当我们通过神经网络运行我们的整个音频剪辑(一次一块)之后,我们将最终得到每个音频块和其最可能被说出的那个字母的一个映射(mapping)。这是一个看起来说”Hello”的映射: 我们的神经网络正在预测我说的那个词很有可能是“HHHEE_LL_LLLOOO”。但它同时认为我说的也可能是“HHHUU_LL_LLLOOO”,或者甚至是“AAAUU_LL_LLLOOO”。 我们遵循一些步骤来整理这个输出。首先,我们将用单个字符替换任何重复的字符: HHHEE_LL_LLLOOO变为HE_L_LO HHHUU_LL_LLLOOO变为HU_L_LO AAAUU_LL_LLLOOO变为AU_L_LO 然后,我们将删除所有空白处: HE_L_LO变为HELLO HU_L_LO变为HULLO AU_L_LO变为AULLO 这让我们得到三种可能的转录 - “Hello”,“Hullo”和“Aullo”。如果你大声说出这些词,所有这些声音都类似于“Hello”。因为它每次只预测一个字符,神经网络会得出一些试探性的转录。例如,如果你说“He would not go”,它可能会给一个可能 “He wud net go” 的转录。 解决问题的诀窍是将这些基于发音的预测与基于书面文本(书籍,新闻文章等)大数据库的可能性得分相结合。你抛弃掉最不可能的转录,而保留住最现实的转录。 在我们可能的转录“Hello”,“Hullo”和“Aullo”中,显然“Hello”将更频繁地出现在文本数据库中(更不用说在我们原始的基于音频的训练数据中),因此它可能是正确的。所以我们会选择“Hello” 而不是其他作为我们的最后的转录。完成! 等一下! 你可能会想“但是如果有人说Hullo”怎么办?这是一个有效的词。也许“Hello”是错误的转录! “Hullo!Who dis? 当然可能有人实际上说“Hullo”而不是“Hello”。但是这样的语音识别系统(基于美国英语训练)基本上不会产生“Hullo”作为转录。用户说“Hullo”,它总是会认为你在说“Hello”,无论你发“U”的声音有多重。 试试看!如果你的手机被设置为美式英语,尝试让你的手机助手识别单词“Hullo”。这不行!它掀桌子不干了(╯‵□′)╯︵┻━┻!它总是会理解为“Hello”。 不识别“Hullo”是一个合理的行为,但有时你会发现令人讨厌的情况:你的手机就是不能理解你说的有效的语句。这就是为什么这些语音识别模型总是被更多的数据训练来修复这些少数情况。 我能建立自己的语音识别系统吗? 机器学习最酷炫的事情之一就是它有时看起来十分简单。你得到一堆数据,把它输入到机器学习算法当中去,然后就能神奇的得到一个运行在你的游戏笔记本电脑的显卡上的世界级AI系统...对吧? 这在某些情况下是真实的,但对于语音识别并不成立。语音识别是一个困难的问题。你必须克服几乎无限的挑战:质量差的麦克风,背景噪音,混响和回声,口音变化,还有很多很多。所有这些问题都需要存在于你的训练数据中,以确保神经网络可以应对它们。 这里有另外一个例子:你知不知道,当你在一个充满噪音的房间里说话时,你不自觉地提高你的音调,以便能够盖过噪音。人类在什么情况下都可以理解你,但神经网络需要训练来处理这种特殊情况。所以你需要人们对着噪音大声说话的训练数据! 要构建一个能在Siri,Google Now!或Alexa等平台上运行的语音识别系统,你将需要大量的训练数据 -如果你不雇佣数百人为你录制的话,它需要的训练数据比你自己能够获得的数据要多得多。由于用户对低质量语音识别系统的容忍度很低,因此你不能吝啬。没有人想要一个只有80%的时间有效的语音识别系统。 对于像谷歌或亚马逊这样的公司,在现实生活中记录的数十万小时的人声语音就是黄金。这就是将他们世界级语音识别系统与你自己的系统拉开差距的地方。让你免费使用Google Now!或Siri或只要50美元购买Alexa而没有订阅费的意义就是:让你尽可能多的使用他们。你对这些系统所说的每一句话都会永远记录下来,并用作未来版本语音识别算法的训练数据。这才是他们的真实目的! 不相信我?如果你有一部安装了Google Now!的Android手机,请点击这里收听你自己对它说过的每一句话: 你可以通过Alexa在Amazon上找到相同的东西。然而,不幸的是,苹果并不让你访问你的Siri语音数据。 因此,如果你正在寻找一个创业的想法,我不建议你尝试建立自己的语音识别系统来与Google竞争。相反,你应该找出一种能让人们把他们说几个小时话的录音给予你的方法。这种数据可以是你的产品。
路在远方… 这个用来处理不同长度音频的算法被称为Connectionist Temporal Classification或CTC。你可以阅读2006年文章。 百度的Adam Coates在湾区深度学习学校做了关于“深度学习语音识别”的精彩演讲。你可以在YouTube上观看这段视频(他的演讲从3分51秒开始)。强烈推荐。
我习惯把语音识别比喻成: 让你识别出图片中的人和猪。(只不过把图片变成了语音) 1.语音的特征提取: 我比喻成识别图片里的人和猪的时候 你是看鼻子还是看耳朵。猪的鼻子比人大 耳朵也比人大 利用这个特征就可以区分开猪和人。 当然在语音领域就是MFCC PLC 基频 等等特征(太多了 查下文献一大堆)。 2.模式识别 这里用的分类器有很多: SVM 向量机 GMM高斯混合模型 ANN人工神经网络等 不同的分类任务 可以选用不同的分类器。 学识浅薄 大概说一下ANN人工神经网络的原理 :你给ANN输入猪的特征(大耳朵大鼻子粉嘟嘟的皮肤) 并告诉ANN 你tm给我记住这是猪!然后ANN就自动调节内部参数 并记住有这种特征就输出:这tm是一头猪! 语音同理:你可以把mfcc等特征 输入ANN并训练它。最后就得到了会语音识别的分类器。 图片里的猪人识别,可以自动换成语音中的病态嗓音识别或是声纹识别。 我还只是刚入门小白 有什么说的不对的地方 你们就乖乖听着(๑˙ー˙๑)
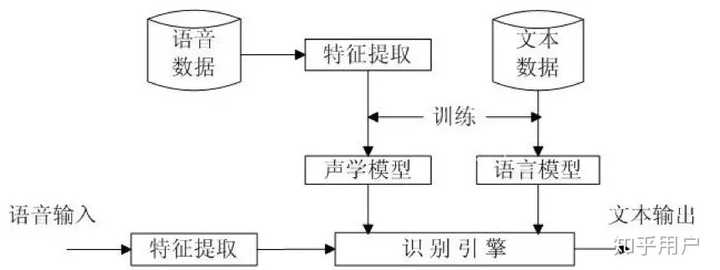
语音识别,是人工智能的重要入口,越来越火。从京东科大讯飞合作的叮咚,亚马逊的明星产品Echo,到最近一个月谷歌Master和百度小度掀起的人机大战,赚够了眼球。但语音只是个入口,内容或者说引导用户做决策乃至消费,才是王道。 基于半年来在语音识别方面的实践心得,结合HTK开源工具,分成两部分来分享对语音识别的原理以及流程的认识。不喜请喷,看完赏赞,手留余香。 第一部分 语音识别系统
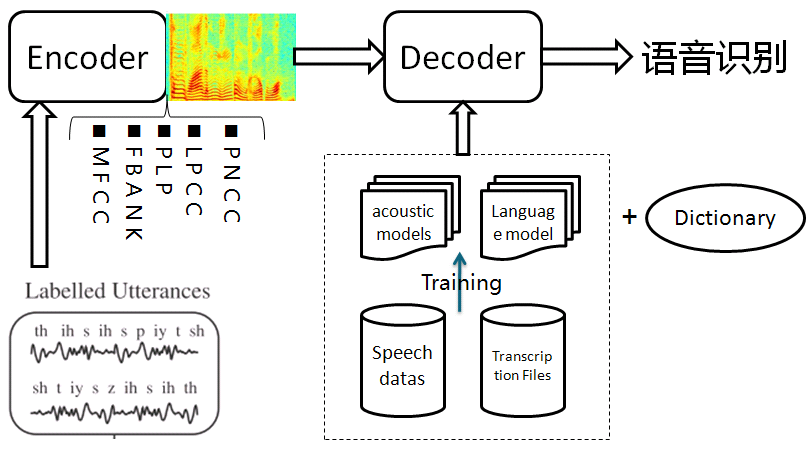
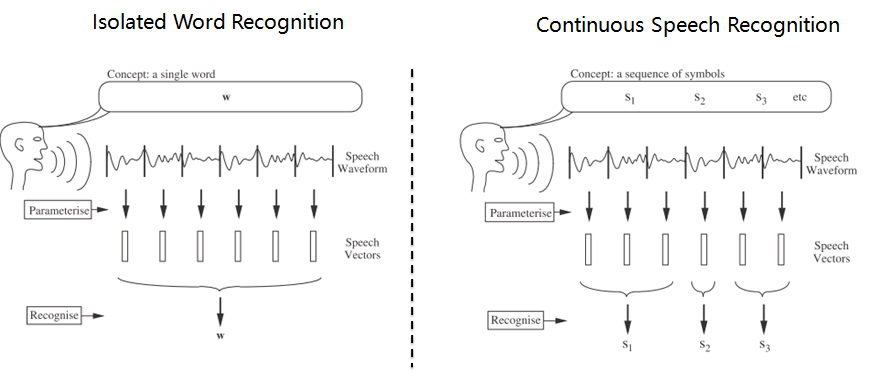
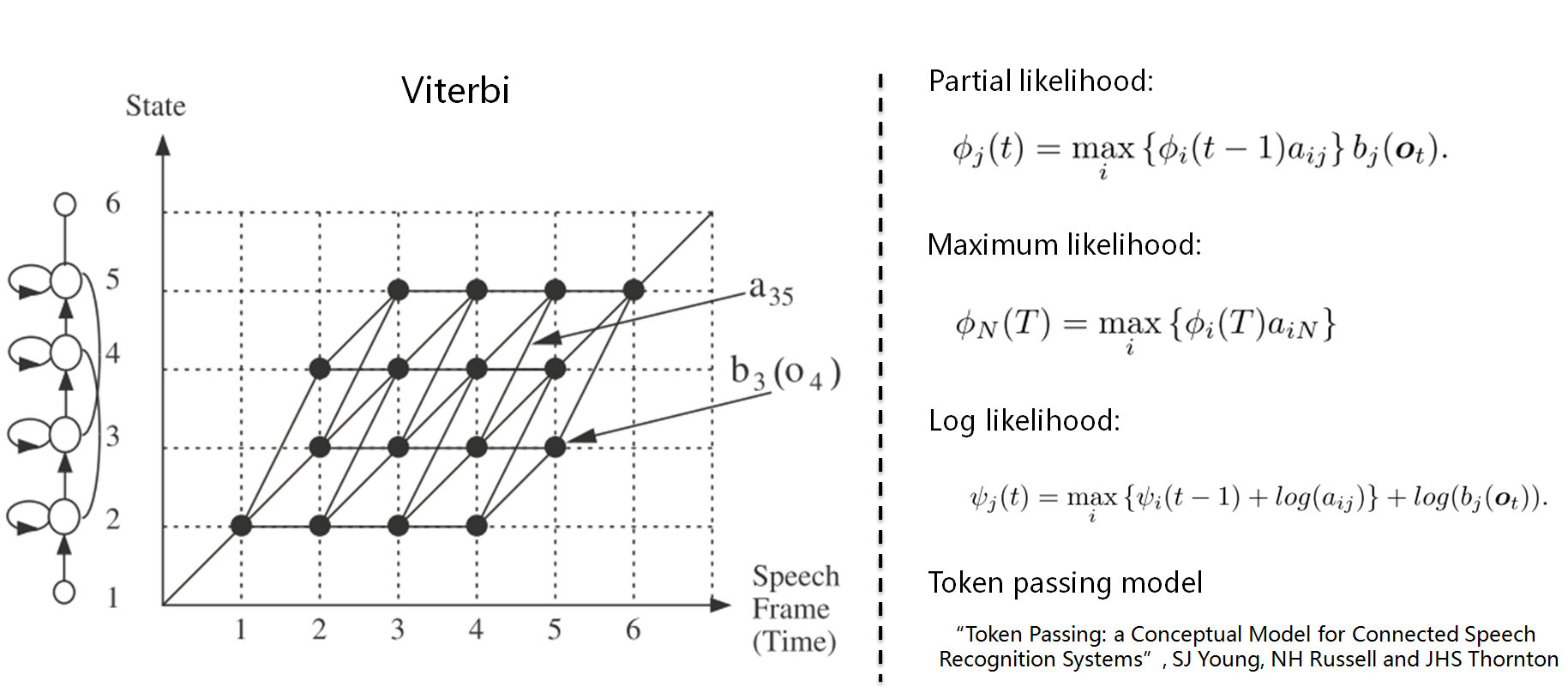
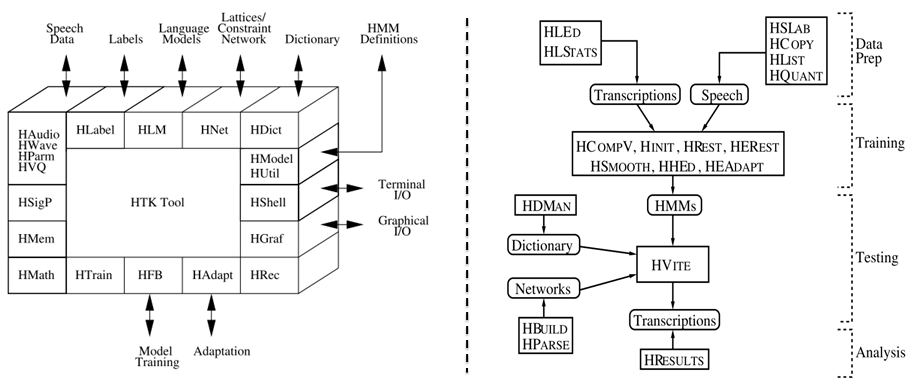
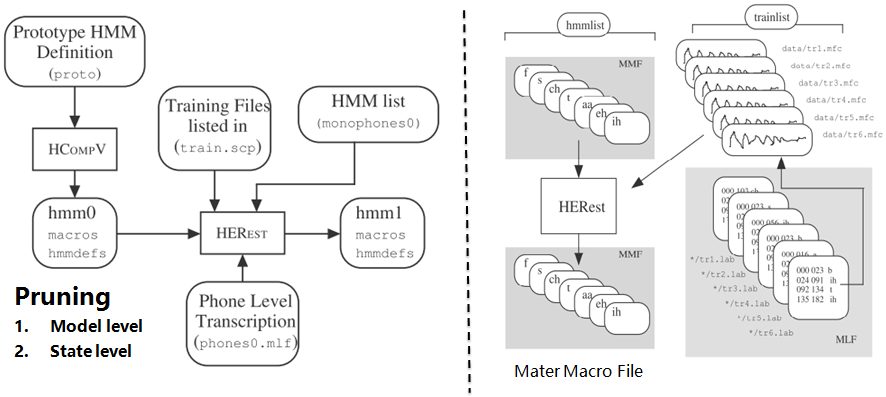
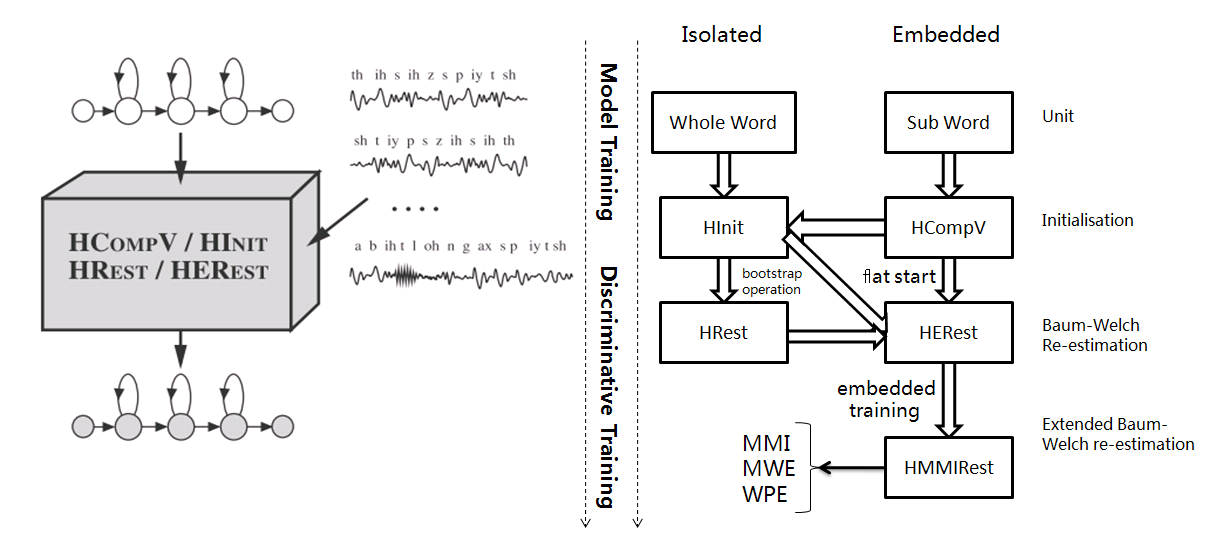
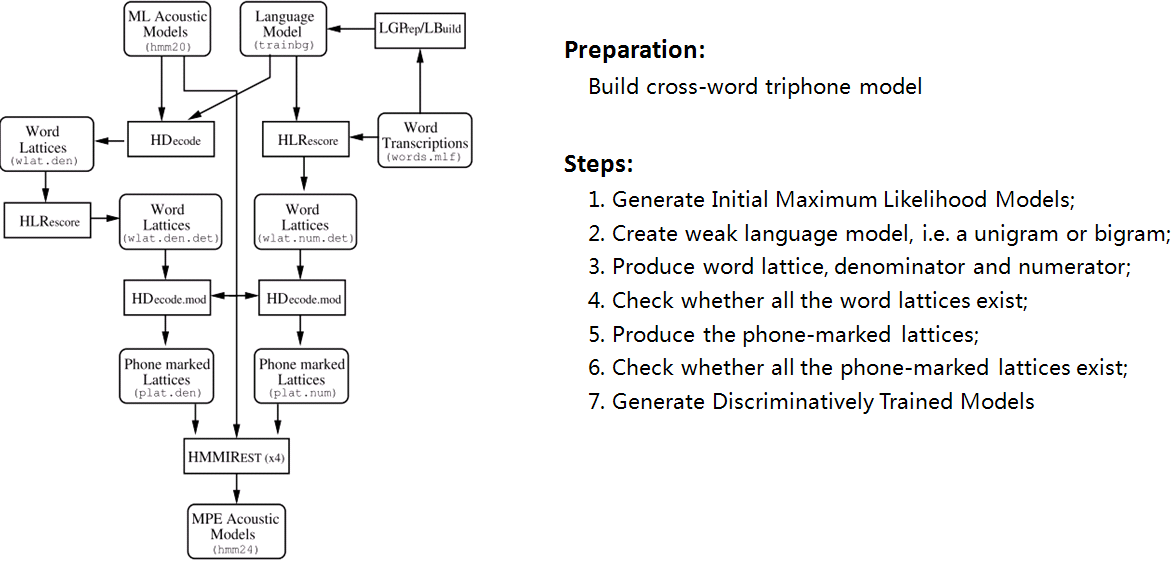
1.语音识别系统的一般架构如左图,分训练和解码两阶段。训练,即通过大量标注的语音数据训练声学模型,包括GMM-HMM、DNN-HMM和RNN+CTC等;解码,即通过声学模型和语言模型将训练集外的语音数据识别成文字。目前常用的开源工具有HTK Speech Recognition Toolkit,Kaldi ASR以及基于Tensorflow(speech-to-text-wavenet)实现端到端系统。我以古老而又经典的HTK为例,来阐述语音识别领域涉及到的概念及其原理。HTK提供了丰富的语音数据处理,以及训练和解码的工具。 2.语音识别,分为孤立词和连续词语音识别系统。早期,1952年贝尔实验室和1962年IBM实现的都是孤立词(特定人的数字及个别英文单词)识别系统。连续词识别,因为不同人在不同的场景下会有不同的语气和停顿,很难确定词边界,切分的帧数也未必相同;而且识别结果,需要语言模型来进行打分后处理,得到合乎逻辑的结果。 3.以孤立词识别为例,能够很好地阐述语音识别的流程级相关概念。假如对词进行建模,在训练阶段学习每个模型的参数;在识别阶段,计算输入语音序列在每个模型的得分(概率值),最高分者获胜。但是,任何语言里的常用单词都以千计,学习数以千计的模型不仅需要庞大的语料库,还需要漫长的迭代时间。此外,汉语还分有调无调,模型数量又成倍增加。 因此,通常对音素建模,然后由音素组合成单词;将极大地降低模型数量,提高训练和解码效率。对英语,常用的音素集是卡内基梅隆大学提供的一套由39个音素构成的音素集(参见The CMU Pronouncing Dictionary)。对汉语,一般用23个声母和24个韵母作为音素集。 4. 采用隐马尔可夫模型(Hidden Markov Model,HMM)对音素建模。1970年,普林斯顿大学的Lenny Baum发明HMM模型,并于20世纪80年代引入到语音识别领域,取得里程碑性的突破。HMM的通俗讲解参见简单易懂的例子解释隐马尔可夫模型。 如上左图,每个音素用一个包含6个状态的HMM建模,每个状态用高斯混合模型GMM拟合对应的观测帧,观测帧按时序组合成观测序列。每个模型可以生成长短不一的观测序列,即一对多映射。训练,即将样本按音素划分到具体的模型,再学习每个模型中HMM的转移矩阵和GMM的权重以及均值方差等参数。 5.参数学习,通过Baum-Welch算法,采用EM算法的思想。因此,每个模型需要初始化,GMM一般采用每个模型对应所有样本的均值和方差。硬分类模式,即计算每帧对应每个状态的GMM值,概率高者获胜;而软分类模式,即每帧都以对应概率值属于对应的状态,计算带权平均。 其中,  表示t时刻的帧  属于状态j的概率。用动态规划前向后向算法计算 。 另外,转移矩阵参数的更新策略: 值得一提,CTC算法的核心就是前向后向算法。 6. 解码,采用Viterbi算法。模型在时间轴上展开的网络中贪婪地寻找最优路径问题,当前路径的联合概率值即为模型得分,选择最优模型,识别出音素,再查找字典,组装成单词。取对数可以避免得分过小的问题。 THK基于Token Passing实现Viterbi算法,用链表记录识别路径信息: 7. HTK开源工具包实现了搭建完整语音识别系统各个环节:录制数据,标注文件,模型初始化与参数学习,以及解码识别,支持语言模型n-gram和RNNLM,实现GPU加速,极大地提高了迭代效率。美中不足的是,目前仅支持前馈型神经网络模型,而且版本更新越来越慢。 8. HTK的历史一览,曾被微软公司收购,最终又回归剑桥大学。从版本更新可知语音识别技术的历史(深度 | 四十年的难题与荣耀--从历史视角看语音识别发展)发展进程。在引入深度学习以前(Hinton 2009),HTK紧跟技术潮流。 第二部分 语音识别概念
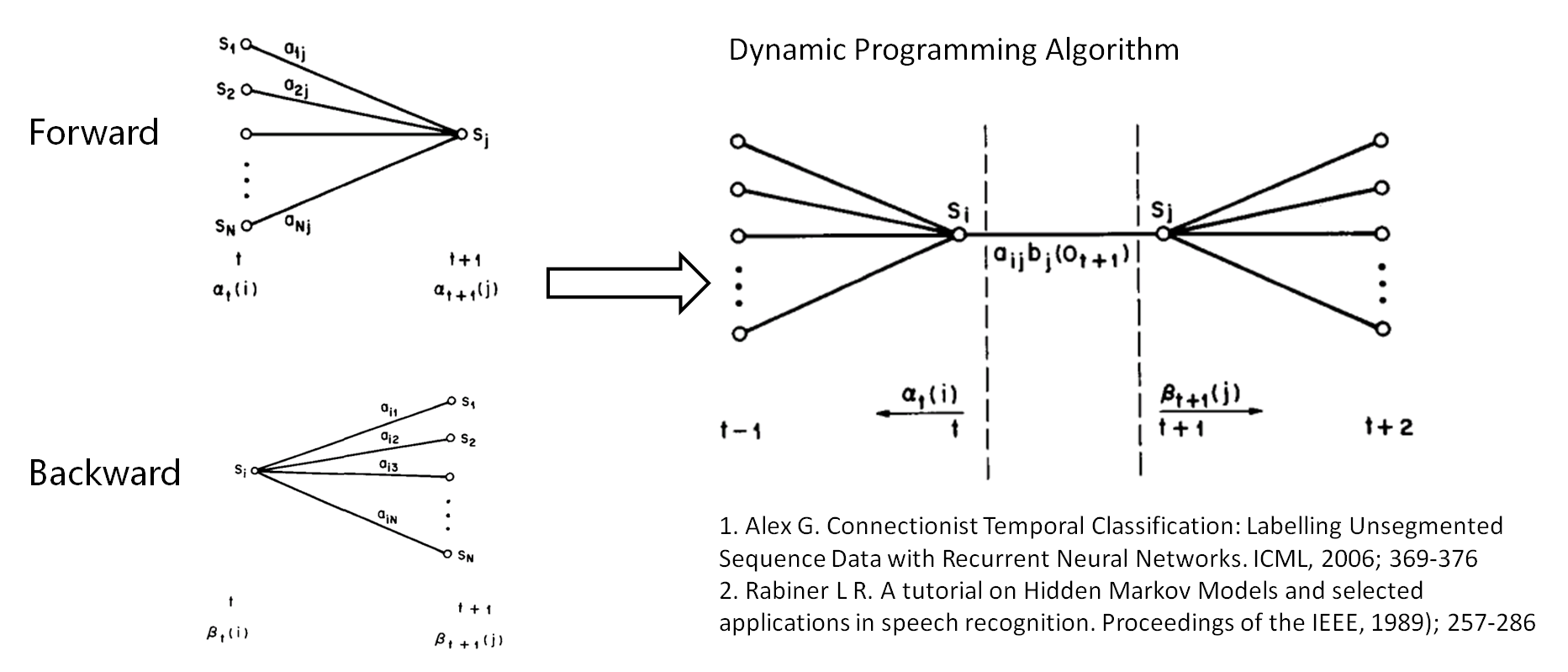
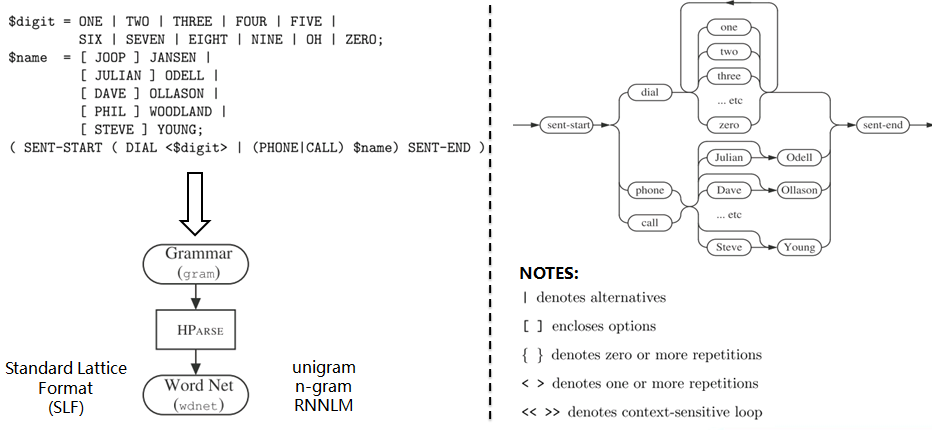
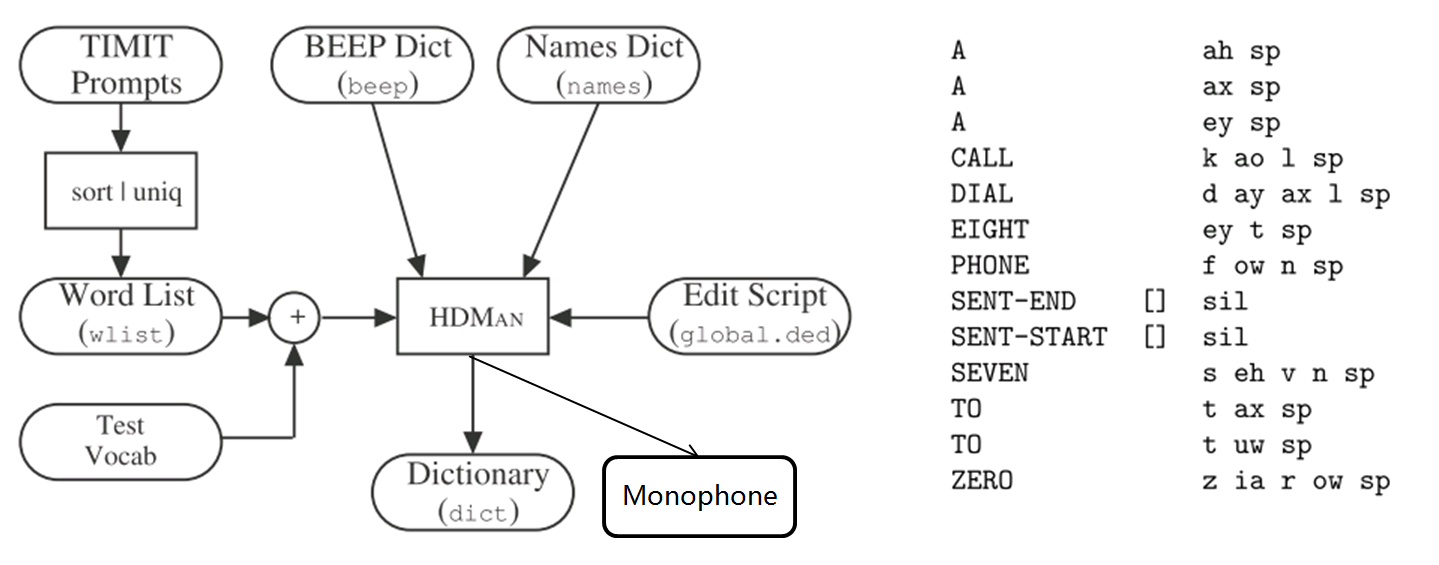
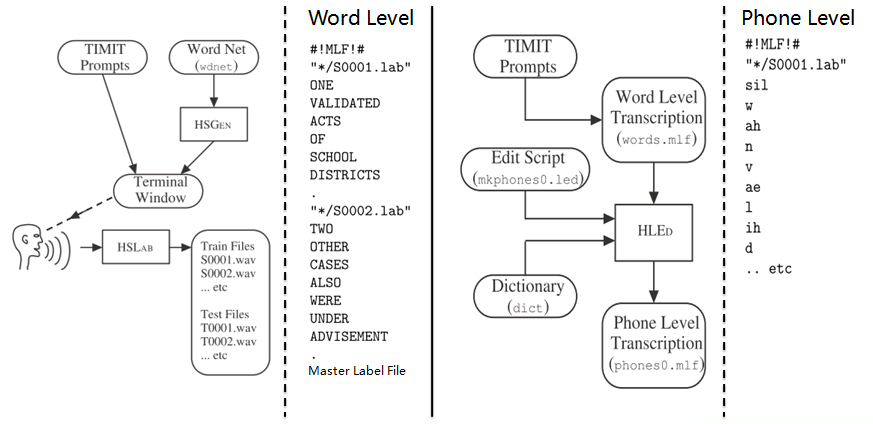
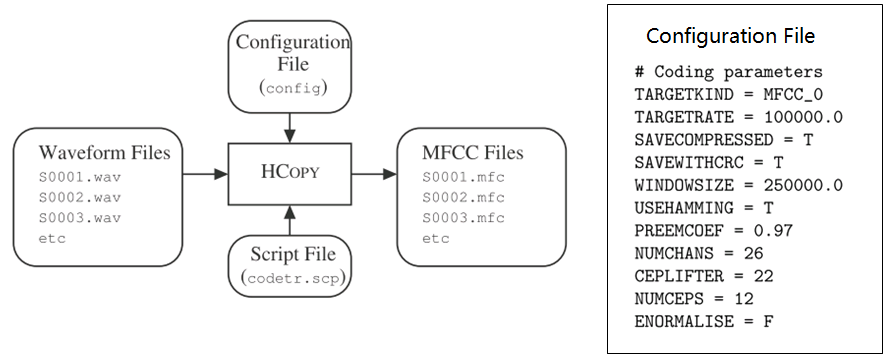
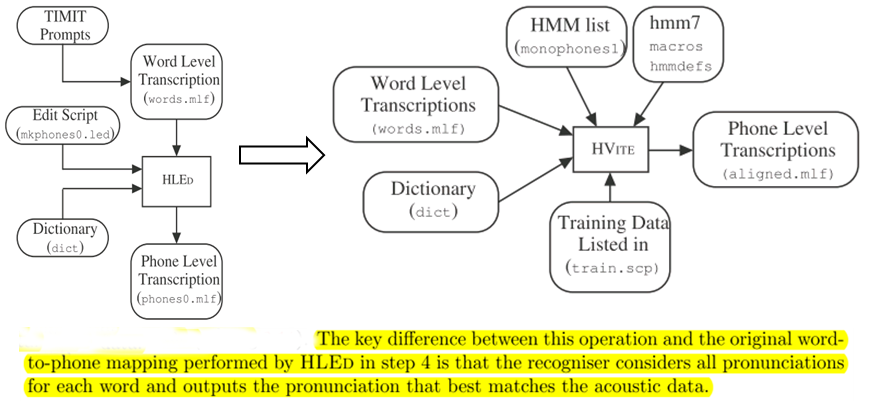
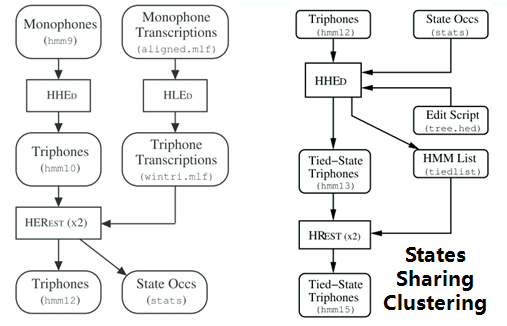
9. Grammar:HParse可以将语法规则(类似于正则表达式的概念)展开成词网络(Word Network),也称词图(Lattice),即限制语音识别的路径,无论什么数据的识别结果都必然是词网络中的一条路径。词网络起到了语言模型的作用;在大规模数据集上,可以被n-gram和RNNLM模型代替。 10. Dictionary: HDMan根据完整的发音字典、词网络中的词以及特定任务中的特定词,生成具体任务的词典和音素表(如果对单音素建模,音素数等于模型数)。如果是对音素建模,首先识别出状态,再根据状态路径的联合概率值识别出音素,音素查找字典组合成单词,单词参考语言模型连接成句子,找到最为匹配的词序作为输出结果。 11. Transcription: 根据词网络可以按需生成标注样本,根据样本采集语音数据。HLEd可以根据字典将词级别的标注文件转换成音素级别的标注,完成处理的数据,可以进一步提取特征或转化成语谱图作为声学模型的输入。 12. Feature: HCopy根据配置文件对音频信号提取特征,常用的有MFCC,即Mel频率倒谱系数。更多语音特征提取参见语音识别特征提取。 13. Training Monophone HMMs: HERest采用处理后的标注数据,根据最大似然(ML)准则,迭代音素文件列表中枚举的模型,直至收敛。其中HCompv采用所有训练样本的均值和方差来初始化GMM的策略,训练数据可以不带标签,非监督初始化。 为了提高迭代效率和排除错误标注数据的影响,参数学习过程中需要裁剪,分为状态级别裁剪或模型级别约束,即定向搜索beam search,按规则约束搜索范围。 14. Realigning: 基于Viterbi算法的帧层次对齐操作,可以纠正偏差的语音标注,生成带时间戳的标注文本,用来再迭代训练模型,提高训练准确率。 15. Triphones HMMs: 基于单音素模型可以构造三音素模型,在音素级别可以利用更多的上下文信息,同时也意味着模型数量的增加。这时需要状态共享和状态聚类技术,降低模型的参数,提高训练效率。
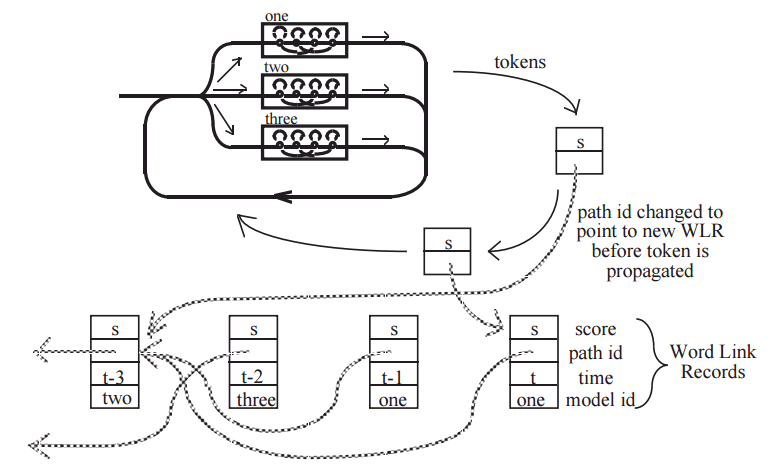
16. Discriminative Training: 模型最大似然输出的结果,根据最大互信息(MMI)和最小音素错误率(WPE)两种训练准则,进一步调整HMM模型的参数,降低识别错误率。HInit利用带标签的语音数据来初始化,并基于Viterbi算法再生成标注文件迭代数次训练模型。 判别性训练的详细参考步骤: 判别性训练,HDecode解码器和DNN-HMM模型等大规模连续词汇识别技术都是基于跨词模式。词内模式的三音素不能跨词连接,因此利用较少的上下文信息,识别性能也较跨词模型差。 17. DNN:之后将近20年,语音识别技术的发展比较缓慢;直至2009年,Hinton将DNN应用于声学建模,并在TIMIT数据集上获得了当时最低的词错率。随着GPU的普及,加速了DNN的发展。采用DNN替换GMM对HMM状态的发射概率进行建模有两大优点:一是不需要对语音数据分布进行假设,不需要切分成stream来分段拟合;DNN的输入可以将相邻语音帧拼接成包含时序结构信息的矢量,在帧层次利用更多的上下文信息。HTK支持基于帧和序列两种训练DNN-HMM模型的方式。 更多参见L09-DNN-Acoustic-Modeling。 18. Decoder: HVite根据声学模型、语言模型和字典识别未知语音,并用HResults来统计分析识别准确率。此外,HTK还支持大规模连续词汇的解码工具HDecode,可以融合更加复杂的语言模型,如3-gram和Recurrent Neural Network Language Models。为了提高识别效率,解码器也支持裁剪,Beam Search。 --------------------------------------------------------------------------------------------------------------------------- 以上分析可知,基于HMM的模型训练需要经过很多细致的步骤,从数据处理及特征提取,到模型初始化,从单音素到三音素的训练和解码,从基于最大似然的训练到基于最大互信息的判别性训练,以及大量的配置文件,需要很高的学习时间成本;为了获得比较好得识别准确率,还需要对齐操作。深度学习的兴起,从开始用DNN代替GMM,发展到现在复杂的LSTM和Deep CNN模型,结合CTC目标函数,甚至attention机制,带来了基于end-to-end的方法,把中间的一些需要人工做的步骤或者需要预处理的部分去掉。 最后,基于Tensorflow实现端到端的Wavenet做中文语音识别。
感谢“点名”。去年老罗在锤子手机发布会上,秀的那段讯飞输入法,其实背后就是语音识别技术。我们拿讯飞输入法这款产品,梳理了背后的技术原理。如右→_→“识别一秒钟,线下十年功” -- 语音输入如何一分钟400字专栏 。祝阅读愉快,也欢迎更多关于语音识别技术的交流、讨论。
鉴于传统架构的语音识别方法在其他的回答中已经有了详细的介绍,这里主要介绍end-to-end语音识别架构,主要涉及到RNN神经网络结构以及CTC。 Outline: 1、 语音识别的基本架构 2、 声学模型(Acoustic Model,AM) - a) 传统模型
- b)CTC模型
- c) end-to-end模型
3、 语言模型 4、 解码 ---------------------------------------------------- 1、 语音识别的基本架构
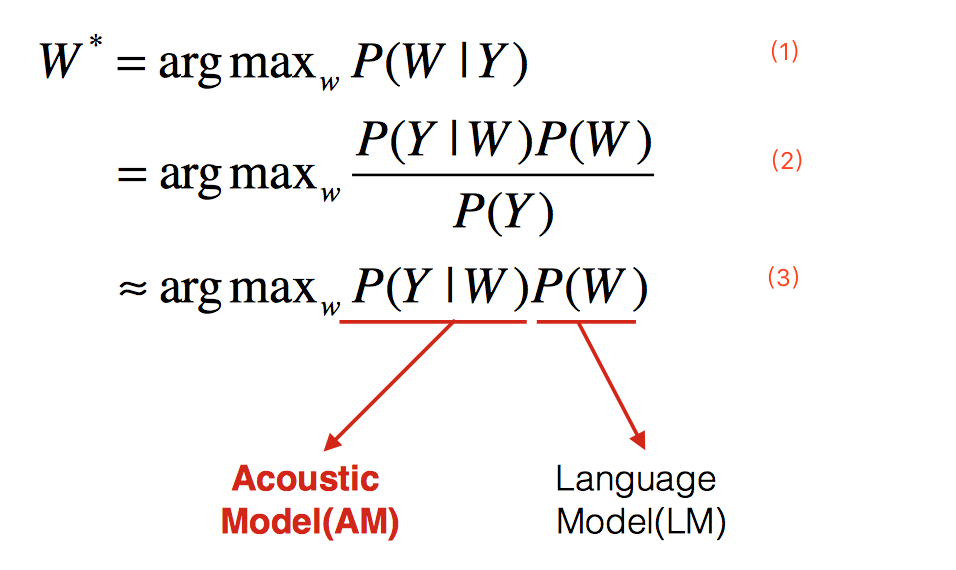
上式中W表示文字序列,Y表示语音输入。公式1表示语音识别的目标是在给定语音输入的情况下,找到可能性最大的文字序列。根据Baye’ Rule,可以得到公式2,其中分母表示出现这条语音的概率,它相比于求解的文字序列没有参数关系,可以在求解时忽略,进而得到公式3。公式3中第一部分表示给定一个文字序列出现这条音频的概率,它就是语音识别中的声学模型;第二部分表示出现这个文字序列的概率,它就是语音识别中的语言模型。
无论是传统的方法也好,现在火热的深 度神经网络的方法也罢,目前的语音识别架构都没有脱离上面的公式,也就是说都离不开AM和LM。下面分别对这两部分进行介绍
2、 声学模型(Acoustic Model,AM)
声学模型可以理解为是对发声的建模,它能够把语音输入转换成声学表示的输出,更准确的说是给出语音属于某个声学符号的概率。
a) 传统模型
在英文中这个声学符号可以是音节(syllable)或者更小的颗粒度音素(phoneme);在中文中这个声学符号可以是声韵母或者是颗粒度同英文一样小的音素。那么公式3中的声学模型就可以表示为下面的公式4的形式:
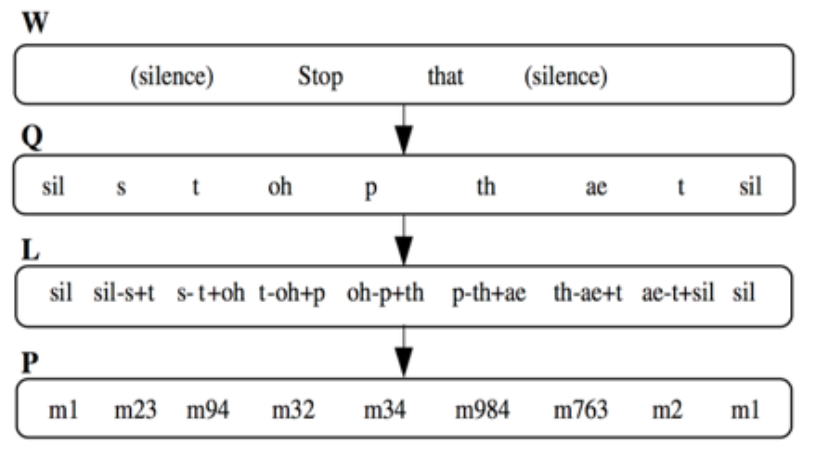
其中Q表示发音单位的序列。从公式中可以看到,声学模型最终转换成了一个语音到发音序列的模型和一个发音序列到输出文字序列的字典。这里的发音序列通常是音素,到此为止声学模型是从语音到音素状态的一个描述。为了对不同上下文的音素加以区分,通常使用上下文相关的“三音子”作为建模单元。可以用下图表示:
其中字典部分表示为如下公式5,其意义是把每个文字拆分成若干发音符号的序列。
公式4中的声学部分可以继续分解为如下公式6 :
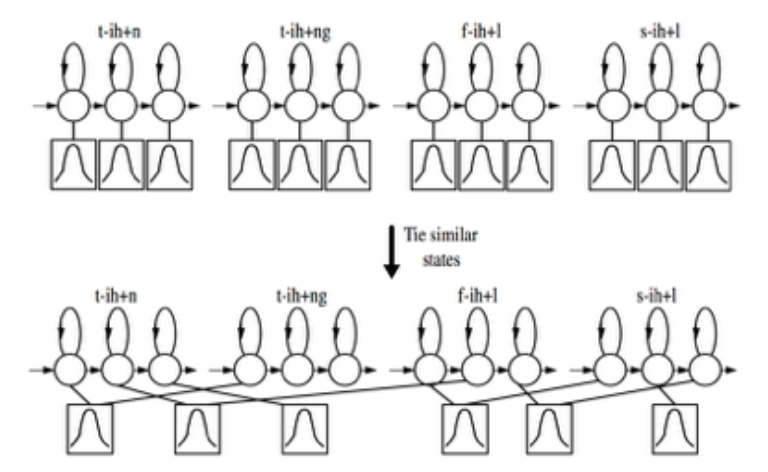
公式6表示声学建模的颗粒度可以继续分解为更小的状态(state)。通常一个三音子对应有3个状态(静音通常是5个状态),那么声学建模的总数就是  这么多。为了压缩建模单元数量,状态绑定的技术被大量使用,它使得发音类似的状态用一个模型表表示,从而减少了参数量。状态绑定的技术可以使用专家手工编撰的规则,也可以使用数据驱动的方式。具体绑定形式如下图所示:
基于上面的推到,声学模型是一个描述语音和状态之间转换的模型。 此时,引入HMM假设:状态隐变量,语音是观测值,状态之间的跳转符合马尔科夫假设。那么声学模型可以继续表示为如下公式:
其中a表示转移概率,b表示发射概率。用图来表示的话就是下图中的结构 :
如图中所示,观测概率通常用GMM或是DNN来描述。这就是CD-GMM-HMM架构[Mark Gales, 2006]和CD-DNN-HMM架构[George E. Dahl, 2012]的语音识别声学模型。CD-DNN-HMM的架构这里引用文章中的图表示如下:
b) CTC模型
在基于CD-DNN-HMM架构的语音识别声学模型中,训练DNN通常需要帧对齐标签。在GMM中,这个对齐操作是通过EM算法不断迭代完成的,而训练DNN时需要用GMM进行对齐则显得非常别扭。因此一种不需要事先进行帧对齐的方法呼之欲出。
此外对于HMM假设一直受到诟病,等到RNN出现之后,使用RNN来对时序关系进行描述来取代HMM成为当时的热潮。
随着神经网络优化技术的发展和GPU计算能力的不断提升,最终使用RNN和CTC来进行建模实现了end-to-end语音识别的声学模型。
CTC的全称是Connectionist Temporal Classification,中文翻译大概是连接时序分类。它要达到的目标就是直接将语音和相应的文字对应起来,实现时序问题的分类。 用公式来描述的话,CTC的公式推导如下: 其中π表示文字序列,X表示语音输入,y表示RNN的输出。由于很多帧可以输出同样的一个文字,同时很多帧也可以没有任何输出,因此定义了一个多对一的函数,把输出序列中重复的字符合并起来,形成唯一的序列,进而公式表示如下: 起始l表示对应的标注文本,而π是带有冗余的神经网络输出。求解上述公式,需要使用前后向算法,定义前向因子 和后向因子: 那么神经网络的输出和前后向因子的关系可以表示为: 进而得到: 利用上述公式,就可以进行神经网络的训练了,这里仍然可以描述为EM的思想: - E-step:使用BPTT算法优化神经网络参数;
- M-step:使用神经网络的输出,重新寻找最有的对齐关系。
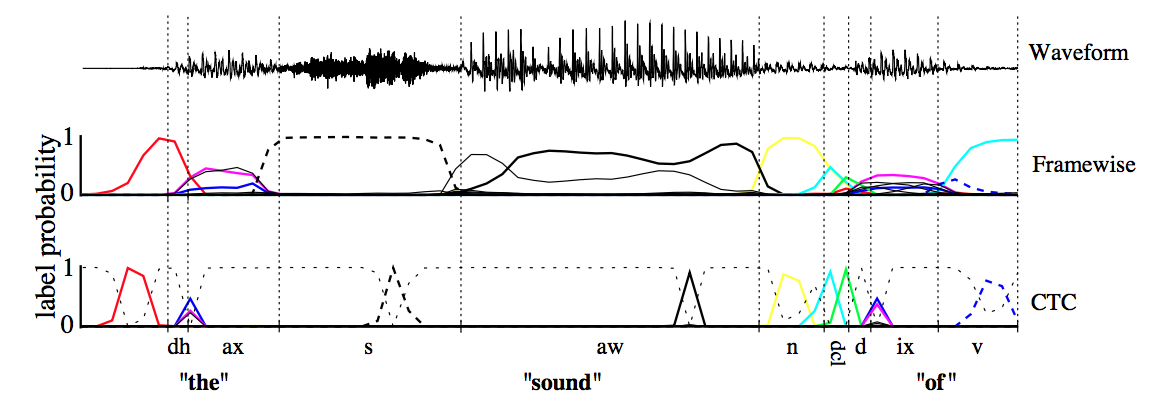
CTC可以看成是一个分类方法,甚至可以看作是目标函数。在构建end-to-end声学模型的过程中,CTC起到了很好的自动对齐的效果。同传统的基于CD-DNN-HMM的方法相比,对齐效果引用文章[Alex Graves,2006]中的图是这样的效果:
这幅图可以理解:基于帧对齐的方法强制要求切分好的帧对齐到对应的标签上去,而CTC则可以时帧的输出为空,只有少数帧对齐到对应的输出标签上。这样带来的差别就是帧对齐的方法即使输出是正确的,但是在边界区域的切分也很难准确,从而给DNN的训练引入错误。
c) End-to-end模型
由于神经网络强大的建模能力,End-to-end的输出标签也不再需要像传统架构一样的进行细分。例如对于中文,输出不再需要进行细分为状态、音素或者声韵母,直接将汉字作为输出即可;对于英文,考虑到英文单词的数量庞大,可以使用字母作为输出标签。
从这一点出发,我们可以认为神经网络将声学符号到字符串的映射关系也一并建模学习了出来,这部分是在传统的框架中时词典所应承担的任务。针对这个模块,传统框架中有一个专门的建模单元叫做G2P(grapheme-to-phoneme),来处理集外词(out of vocabulary,OOV)。在end-to-end的声学模型中,可以没有词典,没有OOV,也没有G2P。这些全都被建模在一个神经网络中。
另外,在传统的框架结构中,语音需要分帧,加窗,提取特征,包括MFCC、PLP等等。在基于神经网络的声学模型中,通常使用更裸的Fbank特征。在End-to-en的识别中,使用更简单的特征比如FFT点,也是常见的做法。或许在不久的将来,语音的采样点也可以作为输入,这就是更加彻底的End-to-end声学模型。
除此之外,End-to-end的声学模型中已经带有了语言模型的信息,它是通过RNN在输出序列上学习得到的。但这个语言模型仍然比较弱,如果外加一个更大数据量的语言模型,解码的效果会更好。因此,End-to-end现在指声学模型部分,等到不需要语言模型的时候,才是完全的end-to-end。
3、 语言模型(Language Model, LM)
语言模型的作用可以简单理解为消解多音字的问题,在声学模型给出发音序列之后,从候选的文字序列中找出概率最大的字符串序列。
关于语言模型,目前最常见的是N-Gram语言模型和基于RNN的语言模型,基于CNN的语言模型facebook也有paper发出来。想深入了解的,可以参考我的这篇回答: 语音识别如何处理汉字中的「同音字」现象? 4、 解码
传统的语音识别解码都是建立在WFST的基础之上,它是将HMM、词典以及语言模型编译成一个网络。解码就是在这个WFST构造的动态网络空间中,找到最优的输出字符序列。搜索通常使用Viterbi算法,另外为了防止搜索空间爆炸,通常会采用剪枝算法,因此搜索得到的结果可能不是最优结果。
在end-to-end的语音识别系统中,最简单的解码方法是beam search。尽管end-to-end的声学模型中已经包含了一个弱语言模型,但是利用额外的语言模型仍然能够提高识别性能,因此将传统的基于WFST的解码方式和Viterbi算法引入到end-to-end的语音识别系统中也是非常自然的。然而由于声学模型中弱语言模型的存在,解码可能不是最优的。文章[yuki Kanda, 2016]提出在解码的时候,需要将这个若语言模型减掉才能得到最优结果。公式推导如下:
其中Pr(s|X)是CTC的声学模型,α是权重系数。语言模型部分推导如下: 其中Pr(s|W)是字符到单词的映射,通常是一对一的。因此上述公式可以表示为如下形式: 其中Pr(W)是传统的语言模型,Pr(s)是字符语言模型,β权重系数。上面的公式表示在CTC的模型解码时,语言模型需要进行减先验的操作,这个先验就是声学训练数据中的字符语言模型。
参考文献: 1、Mark Gales and Steve Young, The Application of Hidden Markov Models in Speech Recognition, 2006 2、George E. Dahl, Dong Yu, Li Deng, and Alex Acero,Context-Dependent Pre-Trained Deep Neural Networks for Large-Vocabulary Speech Recognition,2012 3、Alex Graves,Santiago Fern ́andez,Faustino Gomez,Ju ̈rgen Schmidhuber, Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks,2006 4、Alex Graves , Navdeep Jaitly, Towards End-to-End Speech Recognition with Recurrent Neural Networks, 2014 5、Rafal Jozefowicz, Oriol Vinyals, Mike Schuster, Noam Shazeer, Yonghui Wu, Exploring the Limits of Language Modeling, 2016 6、Naoyuki Kanda, Xugang Lu, Hisashi Kawai, Maximum A Posteriori based Decoding for CTC Acoustic Models, 2016
谢邀,关于这个问题,我们想采用微软首席语音科学家黄学东博士在清华大学的分享——微软是如何利用人工智能技术做好语音识别的,回答这个问题。讲座中,黄学东博士为我们分享了微软在语音识别中取得不断突破背后的技术支持。
————这里是正式回答的分割线————
在几十年的历程中,有非常多优秀的公司在语音和语言领域进行了不懈地探索,终于在今天,达到了和人一样精准的语音识别,这是非常了不起的历史性突破。语言是人类特有的交流工具。今天,计算机可以在假定有足够计算资源的情况下,非常准确地识别你和我讲的每一个字,这是一个非常大的历史性突破,也是人工智能在感知上的一个重大里程碑。
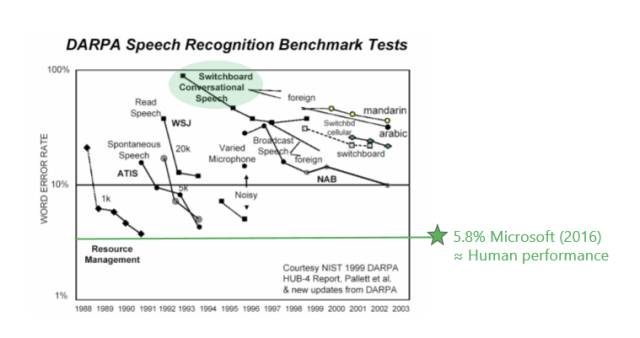
Switchboard是整个工业界常用的一个测试数据集。很多新的领域或新的方法错误率基本都在20%左右徘徊。大规模标杆性的进展是IBM Watson,他们的错误率在5%到6%之间,而人的水平基本上也在5%到6%之间。过去20年,在这个标杆的数据集上,有很多公司都在不懈努力,如今的成果其实并不是一家公司所做的工作,而是整个业界一起努力的结果。
各种各样的神经网络学习方法其实都大同小异,基本上是通过梯度下降法(Gradient Descent)找到最佳的参数,通过深度学习表达出最优的模型,以及大量的GPU、足够的计算资源来调整参数。所以神经网络对计算机语音识别的贡献不可低估。早在90年代初期就有很多语音识别的研究是利用神经网络在做,但效果并不好。因为,第一,数据资源不够多;第二,训练层数少。而由于没有计算资源、数据有限,所以神经网络一直被隐马尔可夫模型(Hidden Markov Model)压制着,无法翻身。
深度学习翻身的最主要原因就是层数的增加,并且和隐马尔可夫模型结合。在这方面微软研究院也走在业界的前端。深度学习还有一个特别好的方法,就是特别适合把不同的特征整合起来,就是特征融合(Feature Fusion)。
如果在噪音很高的情况下可以把特征参数增强,再加上与环境噪音有关的东西,通过深度学习就可以学出很好的结果。如果是远长的语音识别,有很多不同的回音,那也没关系,把回音作为特征可以增强特征。如果要训练一个模型来识别所有人的语音,那也没有关系,可以加上与说话人有关的特征。所以神经网络厉害的地方在于,不需要懂具体是怎么回事,只要有足够的计算资源、数据,都能学出来。
我们的神经网络系统目前有好几种不同的类型,最常见的是借用计算机视觉CNN(Convolution Neural Net,卷积神经网络)可以把不同变化位置的东西变得更加鲁棒。你可以把计算机视觉整套方法用到语音上,把语音看成图像,频谱从时间和频率走,通过CNN你可以做得非常优秀。另外一个是RNN(Recurrent Neural Networks,递归神经网络), 它可以为时间变化特征建模,也就是说你可以将隐藏层反馈回来做为输入送回去。这两种神经网络的模型结合起来,造就了微软历史性的突破。
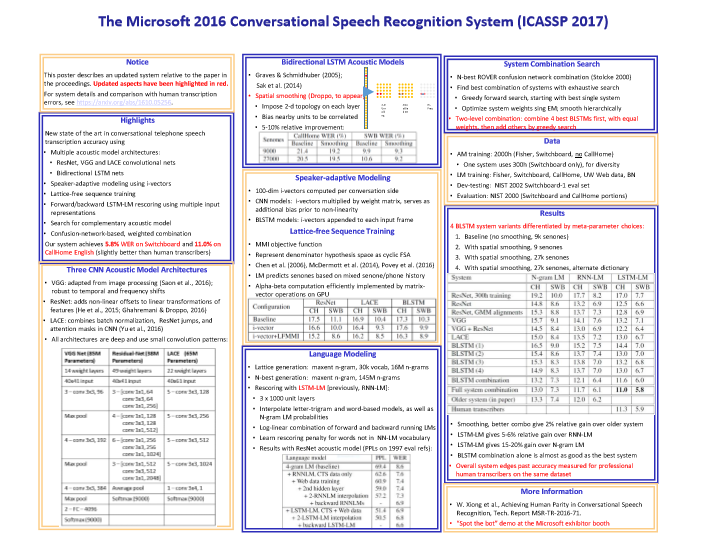
微软语音识别的总结基本上可以用下图来表示。
下图是业界在过去几十年里面错误率下降的指标,可以看到5.8%是微软在去年达到的水平。Switchboard的错误率从80%左右一直到5.8%左右,是用了什么方法呢?我们是怎么达到这个目标呢?
大家知道语音识别有两个主要的部分,一个是语音模型,一个是语言模型。
语音模型我们基本上用了6个不同的神经网络,并行的同时识别。很有效的一个方法是微软亚洲研究院在计算机视觉方面发明的ResNet(残差网络),它是CNN的一个变种。当然,我们也用了RNN。可以看出,这6个不同的神经网络在并行工作,随后我们再把它们有机地结合起来。在此基础之上再用4个神经网络做语言模型,然后重新整合。所以基本上是10个神经网络在同时工作,这就造就了我们历史性的突破。
————这里是回答结束的分割线————
以上回答摘选自回答:语音识别领域的最新进展目前是什么样的水准? 了解黄学东博士的完整演讲内容,请移步:讲堂|黄学东:微软是如何利用人工智能技术做好语音识别的 感谢大家的阅读。 本账号为微软亚洲研究院的官方知乎账号。本账号立足于计算机领域,特别是人工智能相关的前沿研究,旨在为人工智能的相关研究提供范例,从专业的角度促进公众对人工智能的理解,并为研究人员提供讨论和参与的开放平台,从而共建计算机领域的未来。 微软亚洲研究院的每一位专家都是我们的智囊团,你在这个账号可以阅读到来自计算机科学领域各个不同方向的专家们的见解。请大家不要吝惜手里的“邀请”,让我们在分享中共同进步。 也欢迎大家关注我们的微博和微信账号,了解更多我们研究。
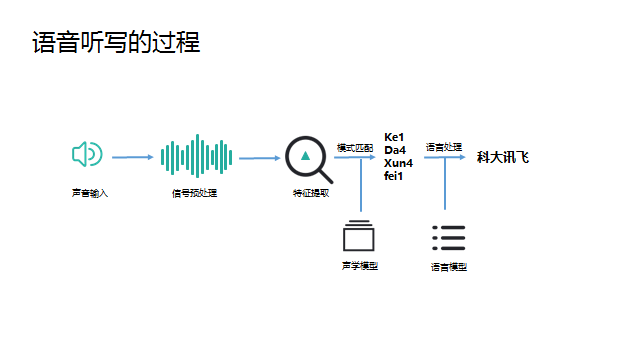
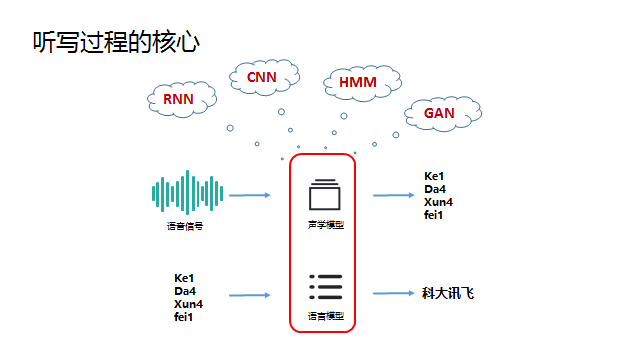
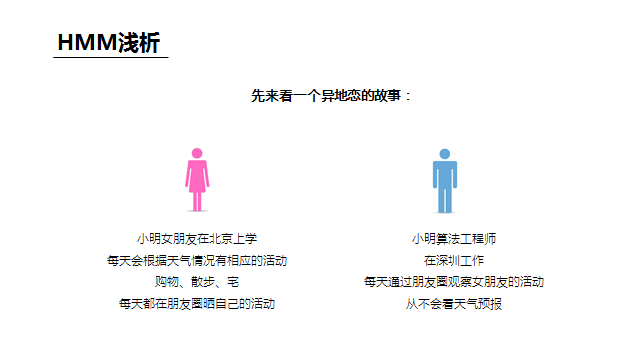
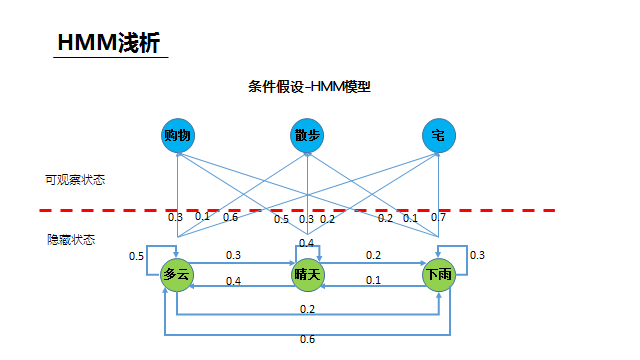
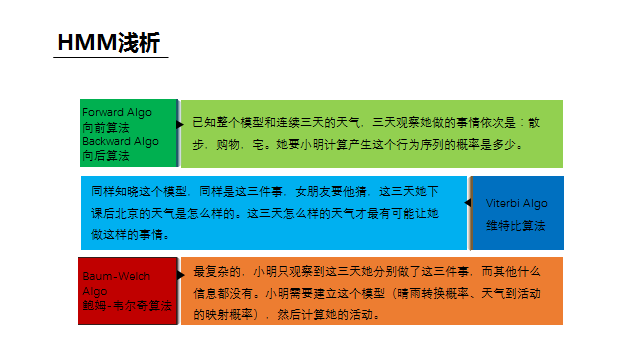
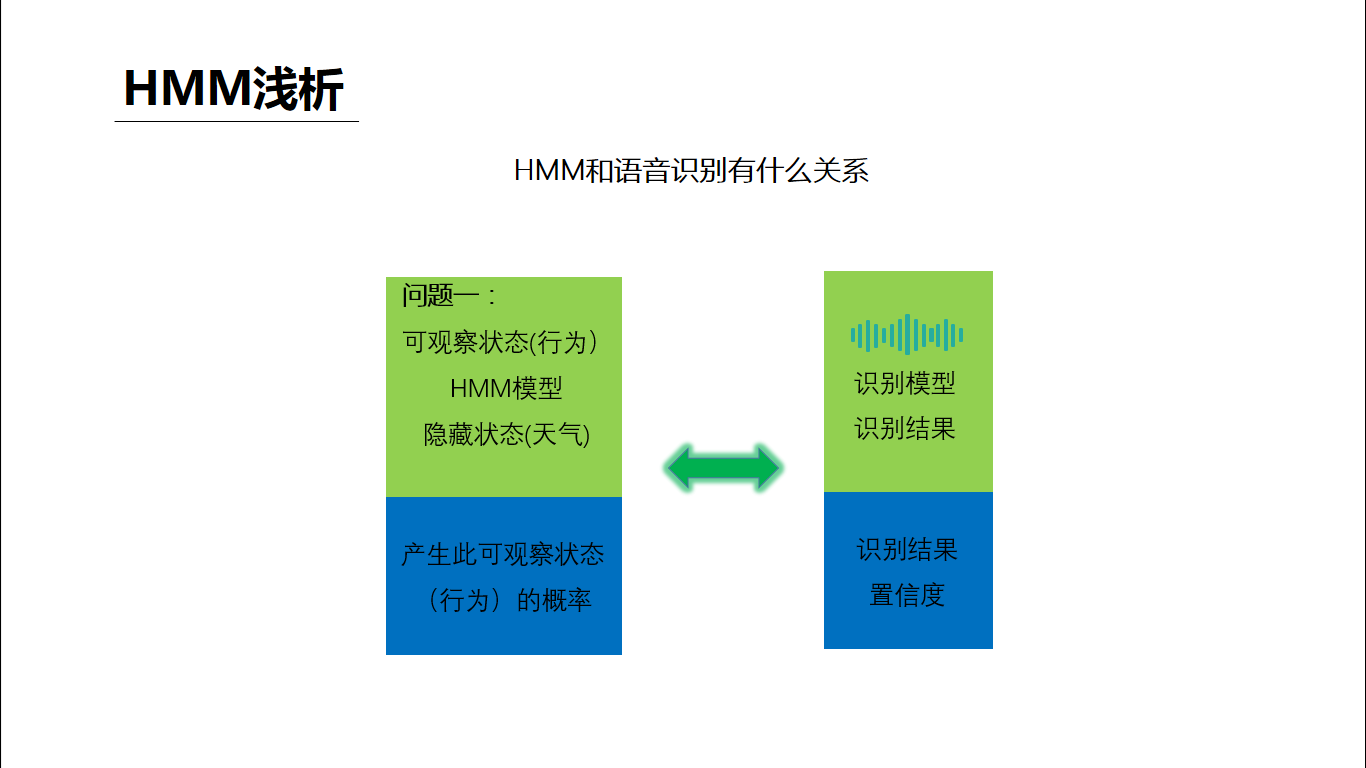
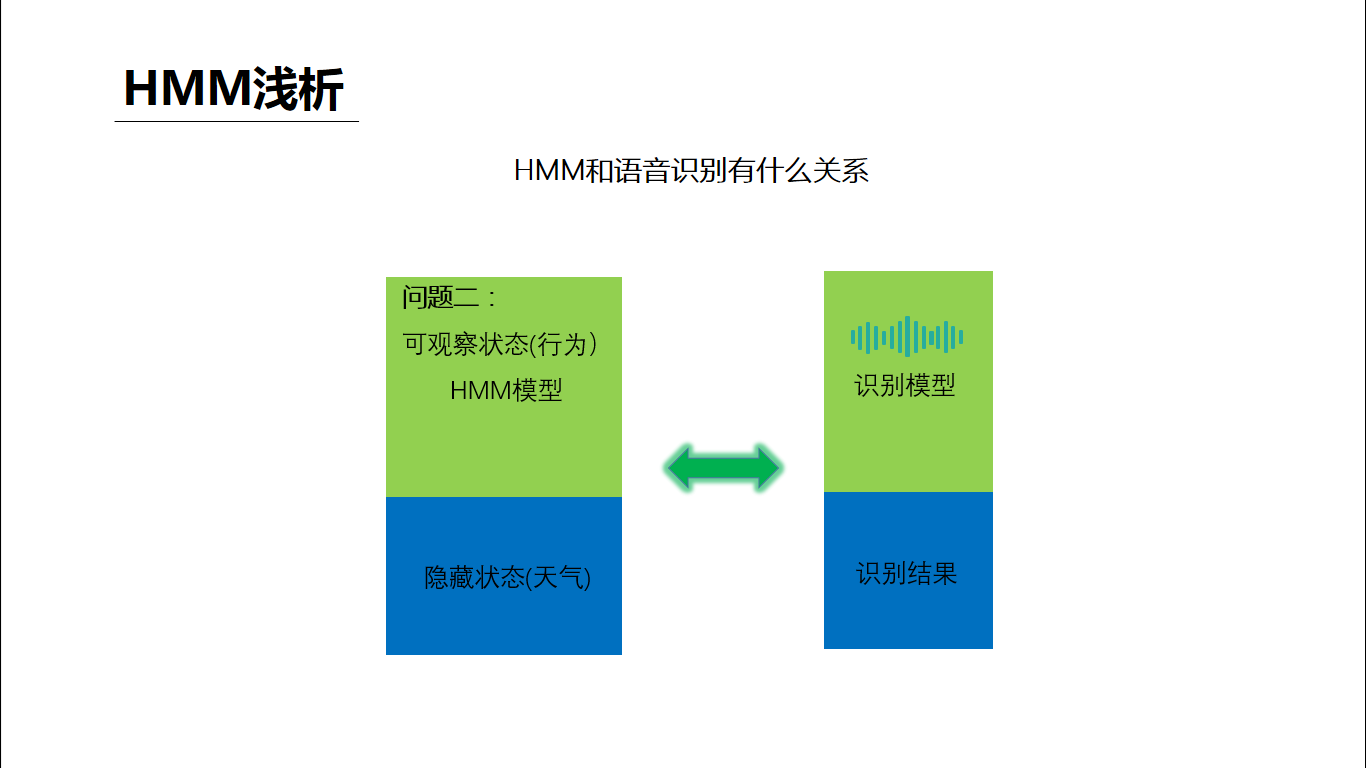
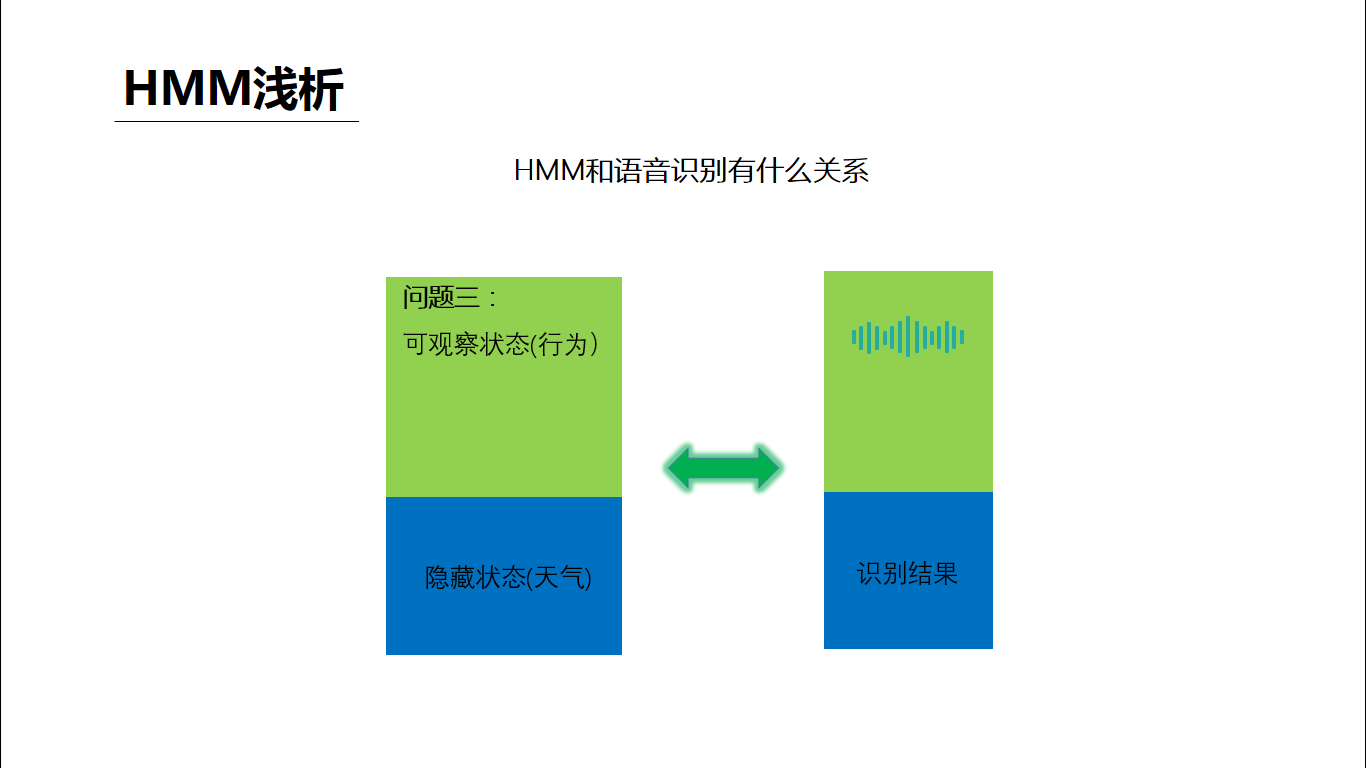
语音识别在专业领域中是一类能力的总称,其中最长用的可能就是语音听写,就是把语音变成对应语言对应内容的文字,下面就以中文语音听写为例简单讲一下我的个人理解。 听写大致的过程:从语音信号的输入开始,需要做VAD、降噪、回声消除等语音预处理得到比较“干净”的声音,然后从中提取出和语音听写相关的特征(语谱图),将特征放到中文声学模型中做声学匹配,可以得到的输入语音的发音信息(可以简单理解为拼音),然后将发音信息放到中文语言模型(类似中文词典)中匹配,可以得到该模型下置信度最高的文字结果。 我们可以明显的发现,整个听写识别过程中两个匹配模型是核心步骤,我们在网络上经常看到的机器学习、各种神经网络等就是在这个核心步骤中发挥作用的。 下面选取最简单的HMM,不写公式、不列方程,用最通俗的例子来说明一下模型匹配的大致原理 如图描述,小明和女朋友的故事背景可以一系列的假设条件,这些其实就构成了一个HMM模型,模型的核心就是隐藏状态和可观察状态之间的转化和相互影响关系。 下面来问题来了,女朋友给小明提了三个问题: 第一个问题类比到语音识别就是,一段语音识别的结果为“科大讯飞”的概率(置信度)是多少 第二个问题类比到语音识别就是,一段语音在某个识别模型下的识别结果是什么(置信度最高的结果) 第三个问题类比到语音识别就是,在没有识别模型的情况下求一段语音的识别结果,这里其实需要小明根据此前一年甚至更久的对天气和女朋友活动状态的观察总结来训练出一个模型,对于小明来说这是历史经验积累,对于机器来说就是机器学习。 回到语音听写的场景下,如下图,这样三个连续的语音信号包含的到底是“是十四”还是“四十四”,我们只需要分别计算出二者的概率(置信度)即可,谁的概率大识别结果就是谁。而图中各项概率参数值就是模型训练优化的结果。 事实上,目前HMM已经几乎没有在语音识别领域的应用了,HMM的优点就是相对少量的数据就可以训练出达到可用程度的模型。而随着大数据的发展,深度学习这个重度依赖数据喂养的怪兽已经基本处于统治地位,相对HMM它的效果瓶颈也更高。 如果读者需要学习了解更多语音相关的理论知识可以参考: AI大学-国内首个AI在线学习平台如果读者需要语音相关的AI能力做应用开发可以参考: 讯飞开放平台-以语音交互为核心的人工智能开放平台
楼上大佬在技术层面已经说的比较透了,这里就对语音识别的历史和一些名词做些白话科普。
语音识别发展史
说到语音识别,大家熟悉的可能是最近十年里才出现的微信语音转文字,或者语音实时记录和翻译。但其实语音识别的历史比互联网还早,现代计算机诞生的那一刻,就已经埋下了语音识别的种子。
1946年,现代计算机诞生。它的诞生让人们意识到,原来计算机能完成这么多工作,而且做得比人还好;
(冯诺依曼和第一台现代计算机)
1950年,图灵在《思想》杂志发表了一篇题为《计算机器和智能》的论文,来探讨计算机是否可以具备智能; 在图灵思想的启发下,人们想着既然计算机这么能干,干嘛不把它设计得和人类一样能看能说能听呢,这不就能帮人类做更多事了嘛!(果然,懒才是科学发展的源动力啊) 于是,第一代语音识别系统诞生,被称为机器的听觉系统。 1952年,贝尔研究所研制了世界上第一个能识别10个英文数字发音的实验系统。也就是你说“yi”,计算机就知道这是“1”,能力跟婴儿差不多。 1960年,英国的Denes等人研制了第一个计算机语音识别系统。 但是因为识别量小,这些系统根本达不到实际应用的要求,包括后续的20年间,都是在走弯路,没有什么研究成果。 直到1970年,统计语言学的出现才使得语音识别重获新生。
统计语言学带来的重生
推动这个技术路线转变的关键人物是德里克·贾里尼克(Frederick Jelinek)和他领导的IBM华生实验室(T.J.Watson)。 统计语言学带来的结果是,让IBM当时的语音识别率从70%提升到90%,同时语音识别的规模从几百单词上升到几万单词,这样语音识别就有了从实验室走向实际应用的可能。
人类的语言是非常复杂的。不同于音频识别,语音识别的难点在于把一段音频不仅转换成对应的字,还要是一段逻辑清晰、语义明确的语句。 举个例子,我们对计算机念一句话,“周五一起吃饭吧”。计算机根据音频做出的识别可能结果是这样的:州午衣起痴范爸。 如果仅看读音和文字的一一对应,这个准确度可以说是很高了,因为如果念的口齿稍有不清更糟糕的结果可能是“邹五意起次换吧”。 但是无论哪种结果,在实际应用上都是不可行的,完全没法交流嘛。
那么统计语言学带来的变革是什么呢? 我们知道,虽然人类的语言很复杂,但仍有一定规律可循,无论是“州午衣起痴范爸”,还是“邹五意起次换吧”都不是一个正常人会说的话。统计语言学的作用就是找出人类说话的规律,这样就可以大大减少了语言识别产生的误差。这其中一个非常关键的概念就是语素。
语素是语言中最小的音义结合体,一个语言单位必须同时满足三个条件——“最小、有音、有义”才能被称作语素。语素又可以分成三类: 单音节语素:构词由一个字才有意思的词组成 双音节语素:构词由两个字才有意思的词组成 多音节语素:构词由两个字以上才有意思的词组成
啥意思呢?举个例子。 你、我、他,这三个字都是单音节语素,因为每个字都能自成一个含义。 你可能要说了,那不是废话吗,还有什么字是没有含义的吗? 当然有!比如挨君最喜欢吃的“馄饨”。
馄饨就是一个双音节语素。单独的馄或者饨都不具备任何含义,只有组合在一起的时候才有真正的意义。类似的还有“琵琶”、“霹雳”等等。另外比如“沙发”这类词,一旦拆分开其含义就完全脱离原来语素的,也被称为双音节语素。
最后一种情况就是多音节语素,主要是专有名词还有拟声词,比如喜马拉雅,动次打次。
我们再看回刚才的例子,当机器知道语素之后,即便同音它也不会把“周五”识别成“州午”,因为后者没有任何意义,也不会把“吃饭”识别成“痴范”。 又有人要说了,现在很多网络用语把吃饭说成次饭,我也能看懂啊。 如果说“次饭”你能理解那当然普大喜奔啦,要是“邹五意起次换吧”你都能理解的话,那对于语音识别团队来说可真是天大的喜讯了。然而真实情况是,视人视场景不同,识别准确率永远是语音识别第一位的追求。
以上,根据语素等人类语言规律挑选同音字的工作,在语音识别中我们称为语言模型。
语言模型的好基友
语音识别中还有一个模型,就是声学模型。 声学模型和语言模型是语音识别里的一对好基友。声学模型负责挑选出与音频匹配的所有同音字,语言模型负责从所有同音字里挑出符合原句意思的字。 声学模型的原理说起来跟做牛肉火锅有点像。
我们拿到一段语音,首先要把它片成若干小段,这个过程叫做分帧。
跟片好的牛肉会被分成匙仁、吊龙、匙柄一样,片好的帧会根据声学特征被计算机算法识别为一个个【状态】,多个状态又可以组合成音素。
音素是语音中的最小的单位,比如哦(o),只有一个音素;我(wo)则有两个音素,w、o;吼(hou),则有三个音素,h、o、u 。 有了音素就可以对应找到匹配的字。
所以你可以这么理解,【状态】就像生牛肉,还不是人类可以“食用”的模样,需要用计算机算法来“涮一涮”成为音素才能成为一个【字】。
PS:如果你对【状态】这个概念还不太理解,那也没关系,因为近几年出现了一个叫CTC的新技术,建模单元放大到了音节或音素的单位,直接跳过了【状态】这个概念,所以这个知识点以后都不会考了。
刚才提到语言模型为语音识别带来的重生,并不是说在此之前声学模型就已经非常成熟了,相反,语音识别重生不久(到20世纪90年代)再次转凉就是因为声学模型太弱。这一状况直到互联网的出现并且带来了极其丰富的大数据后,才稍微得以改善。
语音识别是如何工作的
说完语音识别的两个模型,现在我们可以大致梳理下语音识别的基本步骤,如下图:
你通过微信发送了一段语音,对方因为在开会无法听,于是使用了语音转文字的功能。语音识别系统先把这段语音分帧,然后提取每一帧的特征形成【状态】,几个状态(通常为3个)又会组合成一个音素,音素又构成了诸多同音字,接着语言模型从诸多同音字中挑选出可以使语义完整的字,最后一个个呈现在你面前。
虽然过程看着挺简单的,但事实上,受各种语音语调、方言、说话环境、说话方式等等的影响,语音识别要提高准确率非常非常非常…非 常 难。得亏现在有了大数据和深度学习,这两个模型才得到了好好的训练,包括现在很多语音识别厂商都表示已经可以实现97%的识别准确率。
语音识别作为人机交互的排头兵,起作用至关重要。在语音识别的基础之上还延伸出很多其他的功能,比如声纹识别(身份识别)、语音评测(调整发音)、语音唤醒(智能硬件)等等,大家感兴趣的可以自行了解一蛤。
最后附一张本人最喜欢的图,来源已经找不到了,侵删。
语言作为人类的一种基本交流方式,在数千年历史中得到持续传承。近年来,语音识别技术的不断成熟,已广泛应用于我们的生活当中。语音识别技术是如何让机器“听懂”人类语言?本文将为大家从语音前端处理、基于统计学语音识别和基于深度学习语音识别等方面阐述语音识别的原理。 接下来对语音识别相关技术进行介绍,为了便于整体理解,首先,介绍语音前端信号处理的相关技术,然后,解释语音识别基本原理,并展开到声学模型和语言模型的叙述。
前端信号处理
前端的信号处理是对原始语音信号进行的相关处理,使得处理后的信号更能代表语音的本质特征,相关技术点如下表所述:
1、语音活动检测
语音活动检测(Voice Activity Detection, VAD)用于检测出语音信号的起始位置,分离出语音段和非语音(静音或噪声)段。VAD算法大致分为三类:基于阈值的VAD、基于分类器的VAD和基于模型的VAD。 - 基于阈值的VAD是通过提取时域(短时能量、短时过零率等)或频域(MFCC、谱熵等)特征,通过合理的设置门限,达到区分语音和非语音的目的;
- 基于分类的VAD是将语音活动检测作为(语音和非语音)二分类,可以通过机器学习的方法训练分类器,达到语音活动检测的目的;
- 基于模型的VAD是构建一套完整的语音识别模型用于区分语音段和非语音段,考虑到实时性的要求,并未得到实际的应用。
2、降噪
在生活环境中通常会存在例如空调、风扇等各种噪声,降噪算法目的在于降低环境中存在的噪声,提高信噪比,进一步提升识别效果。
常用降噪算法包括自适应LMS和维纳滤波等。
3、回声消除
回声存在于双工模式时,麦克风收集到扬声器的信号,比如在设备播放音乐时,需要用语音控制该设备的场景。
回声消除通常使用自适应滤波器实现的,即设计一个参数可调的滤波器,通过自适应算法(LMS、NLMS等)调整滤波器参数,模拟回声产生的信道环境,进而估计回声信号进行消除。
4、混响消除
语音信号在室内经过多次反射之后,被麦克风采集,得到的混响信号容易产生掩蔽效应,会导致识别率急剧恶化,需要在前端处理。
混响消除方法主要包括:基于逆滤波方法、基于波束形成方法和基于深度学习方法等。
5、声源定位
麦克风阵列已经广泛应用于语音识别领域,声源定位是阵列信号处理的主要任务之一,使用麦克风阵列确定说话人位置,为识别阶段的波束形成处理做准备。
声源定位常用算法包括:基于高分辨率谱估计算法(如MUSIC算法),基于声达时间差(TDOA)算法,基于波束形成的最小方差无失真响应(MVDR)算法等。
6、波束形成
波束形成是指将一定几何结构排列的麦克风阵列的各个麦克风输出信号,经过处理(如加权、时延、求和等)形成空间指向性的方法,可用于声源定位和混响消除等。
波束形成主要分为:固定波束形成、自适应波束形成和后置滤波波束形成等。
2语音识别的基本原理
已知一段语音信号,处理成声学特征向量之后表示为,其中表示一帧数据的特征向量,将可能的文本序列表示为,其中表示一个词。语音识别的基本出发点就是求,即求出使最大化的文本序列。将通过贝叶斯公式表示为:
其中,称之为声学模型,称之为语言模型。大多数的研究将声学模型和语言模型分开处理,并且,不同厂家的语音识别系统主要体现在声学模型的差异性上面。此外,基于大数据和深度学习的端到端(End-to-End)方法也在不断发展,它直接计算 ,即将声学模型和语言模型作为整体处理。本文主要对前者进行介绍。
3声学模型
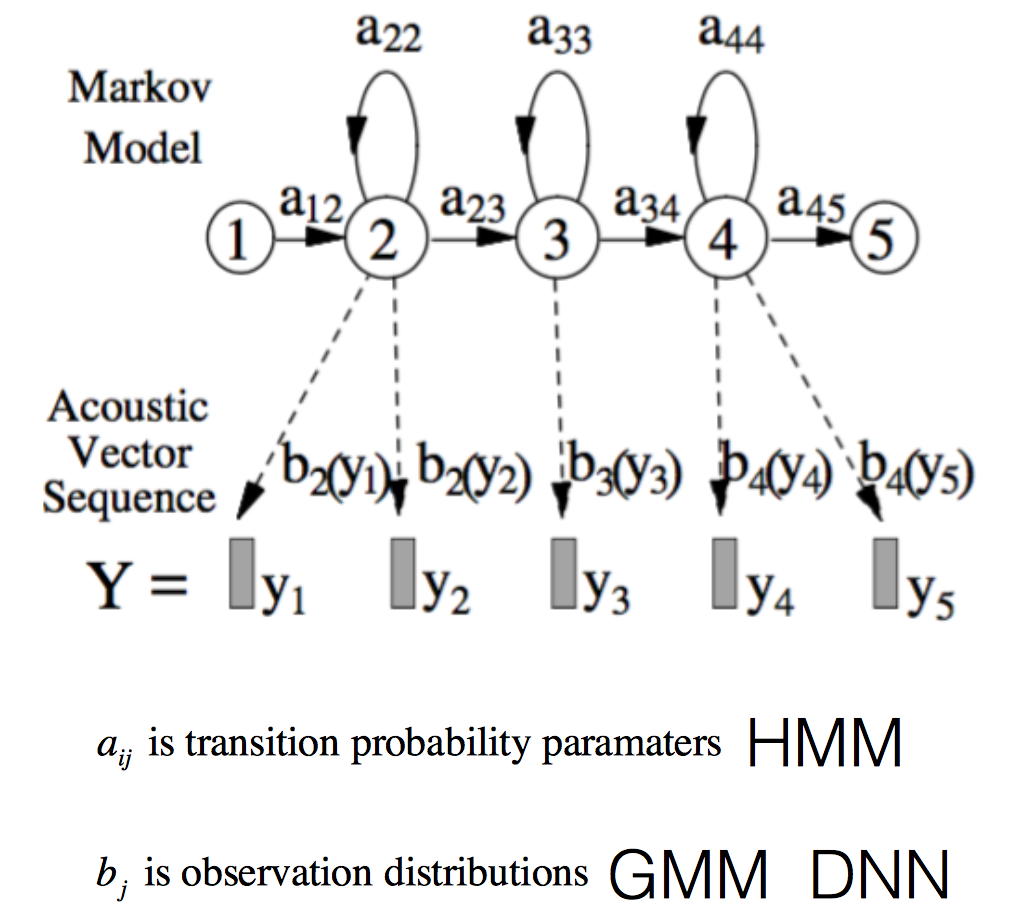
声学模型是将语音信号的观测特征与句子的语音建模单元联系起来,即计算。我们通常使用隐马尔科夫模型(Hidden Markov Model,HMM)解决语音与文本的不定长关系,比如下图的隐马尔科夫模型中。
将声学模型表示为
其中,初始状态概率和状态转移概率可用通过常规统计的方法计算得出,发射概率 )可以通过混合高斯模型GMM或深度神经网络DNN求解。
传统的语音识别系统普遍采用基于GMM-HMM的声学模型,示意图如下:
其中,表示状态转移概率,语音特征表示,通过混合高斯模型GMM建立特征与状态之间的联系,从而得到发射概率,并且,不同的状态对应的混合高斯模型参数不同。
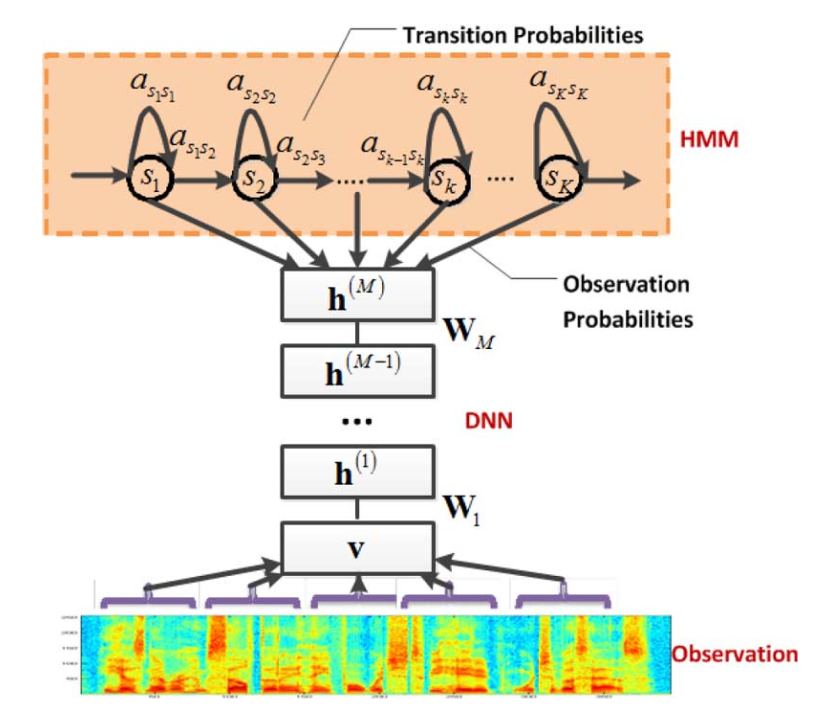
基于GMM-HMM的语音识别只能学习到语音的浅层特征,不能获取到数据特征间的高阶相关性,DNN-HMM利用DNN较强的学习能力,能够提升识别性能,其声学模型示意图如下:
GMM-HMM和DNN-HMM的区别在于用DNN替换GMM来求解发射概率,GMM-HMM模型优势在于计算量较小且效果不俗。DNN-HMM模型提升了识别率,但对于硬件的计算能力要求较高。因此,模型的选择可以结合实际的应用调整。
4语言模型
语言模型与文本处理相关,比如我们使用的智能输入法,当我们输入“nihao”,输入法候选词会出现“你好”而不是“尼毫”,候选词的排列参照语言模型得分的高低顺序。
语音识别中的语言模型也用于处理文字序列,它是结合声学模型的输出,给出概率最大的文字序列作为语音识别结果。由于语言模型是表示某一文字序列发生的概率,一般采用链式法则表示,如是由组成,则可由条件概率相关公式表示为:
由于条件太长,使得概率的估计变得困难,常见的做法是认为每个词的概率分布只依赖于前几个出现的词语,这样的语言模型成为n-gram模型。在n-gram模型中,每个词的概率分布只依赖于前面n-1个词。例如在trigram(n取值为3)模型,可将上式化简:
—————————————————————————————————— 结尾福利放送,整理的2018/2019/校招/春招/秋招/自然语言处理/深度学习/机器学习知识要点及面试笔记,送给急需提升的朋友,希望在明年春招来临的时候能助你一臂之力。(关注公众号语音杂谈并回复GH就能获得所有资料)
该仓库整理了“花书”《深度学习》中的一些常见问题,其中部分偏理论的问题没有收录,如有需要可以浏览原仓库。此外,还包括作者看到的所有机器学习/深度学习面经中的问题。除了其中 DL/ML 相关的,其他与算法岗相关的计算机知识也会记录。但是不会包括如前端/测试/JAVA/Android等岗位中有关的问题。
语音识别是什么?他有什么价值,以及他的技术原理是什么?本文将解答大家对语音识别的常见疑问。 语音识别技术(ASR)是什么?
机器要与人实现对话,那就需要实现三步: 对应的便是“耳”、“脑”、“口”的工作,机器要听懂人类说话,就离不开语音识别技术(ASR)。
语音识别已经成为了一种很常见的技术,大家在日常生活中经常会用到: - 苹果的用户肯定都体验过 Siri ,就是典型的语音识别
- 微信里有一个功能是”文字语音转文字”,也利用了语音识别
- 最近流行的智能音箱就是以语音识别为核心的产品
- 比较新款的汽车基本都有语音控制的功能,这也是语音识别
语音识别技术讲解
语音识别技术拆分下来,主要可分为“输入——编码——解码——输出 ”4个流程。
那语音识别是怎么工作的呢? 首先声音的本身是一种波,就像我们常常用一段段波形来表示音频一样。 接下来按步骤: - 给音频进行信号处理后,便要按帧(毫秒级)拆分,并对拆分出的小段波形按照人耳特征变成多维向量信息
- 将这些帧信息识别成状态(可以理解为中间过程,一种比音素还要小的过程)
- 再将状态组合形成音素(通常3个状态=1个音素)
- 最后将音素组成字词(dà jiā hǎo)并串连成句 。于是,这就可以实现由语音转换成文字了。
更多扩展阅读可以看看下面的完整版 「深入浅出」了解语音识别的技术原理和价值? - easyAI 人工智能知识库
参见文章: stephon:Speech Recognition(1)stephon:Speech Recognition(2)stephon:Speech Recognition(3)stephon:Speech Recognition(4)stephon:Speech Recognition(5)stephon:Speech Recognition(6)stephon:Speech Recognition(7)
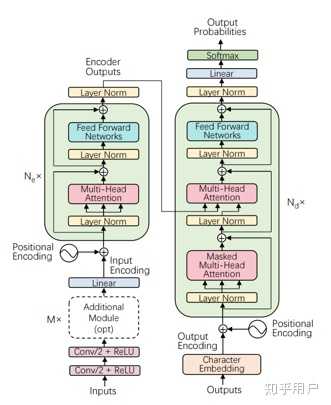
我们先明确端到端语音识别的输入和输出。 输入是 Mel谱(MFCC特征),可以理解为将语音信号经过采样,大约每10毫秒可以得到一个向量,向量的维度一般是80,如果语音有10秒,整个mel input的就是一个 80 * 1000 的矩阵。这和NLP中的word embedding输入十分类似,但是NLP的文本长度大部分任务会比语音短一些。 输出是一串Subword,和NLP类似,目前Subword是最好的端到端系统的输出单位,一般用sentence piece等工具将文本进行切分。 -------------------------模型分割线------------------------- 端到端模型粗略可以分为label-sync和frame-sync,label-sync可以理解为NLP之中传统的beam search方案,给定音频输入,解码器每个time step解码一个词语,beam search时候会保存beam size个结果,直到解码出 符号。典型的label-sync的模型是经典的Seq2Seq模型 Seq2Seq: 随着基于Transformer的模型的兴起,当下最流行的模型结构是Transformer,和传统NLP中Transformer不同的是,开始时候如果使用CNN对语音输入进行处理,会提升语音识别的最终性能。 至于其他都和Transformer S2S没有本质区别。然而所有的Seq2Seq ASR模型都有两个缺点:其一是很难处理流式的输入(用户边说边识别),其二是输出的文字结果有可能非常短,需要一些coverage的操作才可以避免这个问题。 在这里打一个小广告,我们开源的StreamingTransformer系统,以及其背后的Offline Transformer结构目前都是英文语音识别数据集Librispeech Seq2Seq同参数的比较下最好的系统,尤其是这种流式的Transformer处理方式,应该比其他的流式模型在Librispeech数据集都好很多。 https://github.com/cywang97/StreamingTransformer
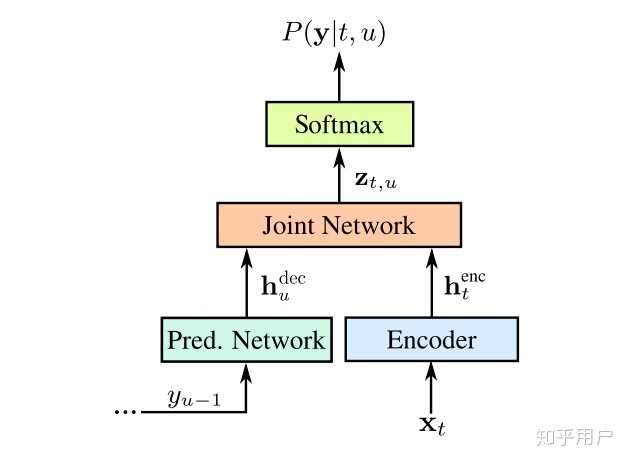
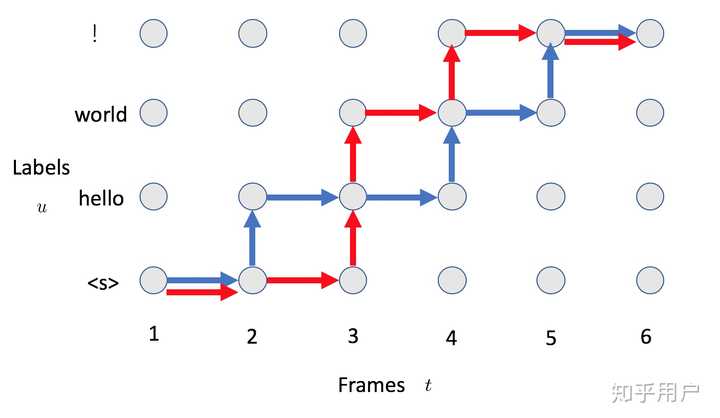
说完label-sync,转到另一个方案。frame-sync十分有语音的特色,给每一个frame都打一个标签,标签可以为空,如下图所示,五帧每个对应一个word,代表空 然而,一个明显的问题浮现出来了,如何自动对齐frame和label,这就引出了语音里面最经典的模型CTC以及他的衍生品Transducer。CTC和Transducer说到底是一个loss function,它十分明确的定义了一个优化目标,它并不是一个网络结构,而是利用RNN或者Transformer对每个frame输出之后,定义了一个loss,让两个不等长序列X和Y可以一个frame和一个word对应上(通过给word集合加入空,以及CTC中相邻两个frame可以是一个词) CTC 我简单总结一下,首先encoder会在每个frame输出一个词的distribution,且frame之间没有依赖,如果词典5000(含空),那么输出就是5000,之后CTC会给所有合法路径算概率,例如上图的hello world有5帧,那么其他的合法路径还有hello world ,hello world 等等。之后会计算每个路径的概率(概率比较好算,就是step概率的乘积),CTC把所有这些合法路径加起来,并进行优化 Transducer Transducer可以理解为CTC的衍生品,因为CTC在建模的时候第i个词只与X有关,没有考虑之前输出的词语  ,所以会在语言模型上有些问题,在实际应用中往往需要搭配语言模型使用。所以,Transducer在建模的时候改变了这一个问题,它建模的是  ,考虑了额外的语言模型部分,模型图如下所示 Encoder会给每一个frame一个hidden state,之后还有个preditor network,它会根据已经输出的序列给出下一个词的hidden state,然后两个一拼,得到了该时刻词语分布的概率。之后仍旧是动态规划,如果是空就横着走,否则竖着走,算出所有合法路径的概率,优化 RNN-T由于是frame sync模型,且克服了CTC没有建模词语互相的关系,是非常适合工业界的流式模型,也是目前Google device上上线的流式模型,只是训练时候显存消耗非常大,不太好训练。
最后一些个人想说的: 1 目前,seq2seq仍然是给定完整音频,之后进行识别,准确率最佳方案。前提是结合一些防止生成太短的技术 2 流式的情况下,transducer或者ctc加lm可以根据资源选用,如果卡少只能ctc 3 seq2seq流模型比较复杂,虽然性能也不错但经常换了数据集会出问题 4 Transformer比RNN更适合建模长一些的语音序列,短的差不多,而且RNN跑得快。
谢邀! 不同的算法框架,识别原理也不一样,下面是灵声讯音频-语音算法实验室整理创作的比较全的算法原理简述,希望能帮到你! 语音识别技术简述(概念->原理)
目录 语音识别技术简述(概念->原理) 语音识别概念 语音识别原理 语音识别技术简介 1.动态时间规整(DTW) 2.支持向量机(SVM) 3.矢量量化(VQ) 4.隐马尔科夫模型(HMM) 5.高斯混合模型(GMM) 6.人工神经网络(ANN/BP) 7.深度神经网络/深信度网络-隐马尔科夫(DNN/DBN-HMM) 8.循环神经网络(RNN) 9.长短时记忆模块(LSTM) 10.卷积神经网络(CNN) 识别技术的发展方向 参考文献
本内容部分原创,因作者才疏学浅,偶有纰漏,望不吝指出。本内容由灵声讯音频-语音算法实验室整理创作,转载和使用请与“灵声讯”联系,加qun方式:音频/识别/合成算法QQ群
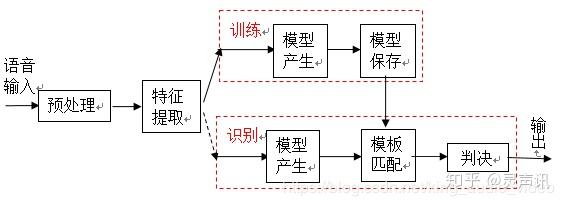
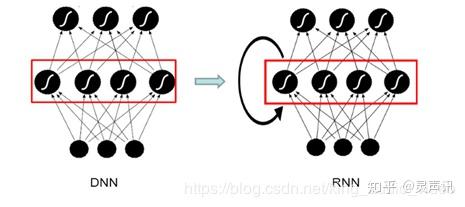
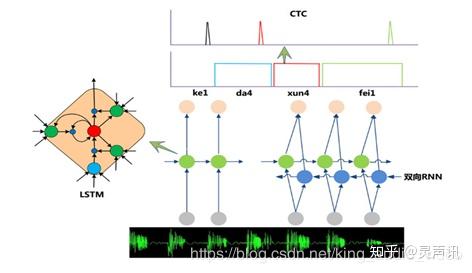
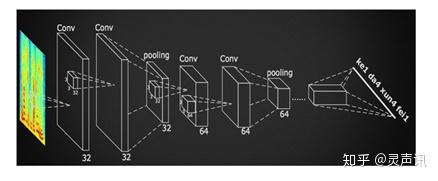
语音识别概念语音识别技术就是让智能设备听懂人类的语音。它是一门涉及数字信号处理、人工智能、语言学、数理统计学、声学、情感学及心理学等多学科交叉的科学。这项技术可以提供比如自动客服、自动语音翻译、命令控制、语音验证码等多项应用。近年来,随着人工智能的兴起,语音识别技术在理论和应用方面都取得大突破,开始从实验室走向市场,已逐渐走进我们的日常生活。现在语音识别己用于许多领域,主要包括语音识别听写器、语音寻呼和答疑平台、自主广告平台,智能客服等。 语音识别原理语音识别的本质是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。目前,模式匹配原理已经被应用于大多数语音识别系统中。如图1是基于模式匹配原理的语音识别系统框图。 一般的模式识别包括预处理,特征提取,模式匹配等基本模块。如图所示首先对输入语音进行预处理,其中预处理包括分帧,加窗,预加重等。其次是特征提取,因此选择合适的特征参数尤为重要。常用的特征参数包括:基音周期,共振峰,短时平均能量或幅度,线性预测系数(LPC),感知加权预测系数(PLP),短时平均过零率,线性预测倒谱系数(LPCC),自相关函数,梅尔倒谱系数(MFCC),小波变换系数,经验模态分解系数(EMD),伽马通滤波器系数(GFCC)等。在进行实际识别时,要对测试语音按训练过程产生模板,最后根据失真判决准则进行识别。常用的失真判决准则有欧式距离,协方差矩阵与贝叶斯距离等。 图1. 语音识别原理架图 从语音识别算法的发展来看,语音识别技术主要分为三大类,第一类是模型匹配法,包括矢量量化(VQ) 、动态时间规整(DTW)等;第二类是概率统计方法,包括高斯混合模型(GMM) 、隐马尔科夫模型(HMM)等;第三类是辨别器分类方法,如支持向量机(SVM) 、人工神经网络(ANN)和深度神经网络(DNN)等以及多种组合方法。下面对主流的识别技术做简单介绍: 1.动态时间规整(DTW)语音识别中,由于语音信号的随机性,即使同一个人发的同一个音,只要说话环境和情绪不同,时间长度也不尽相同,因此时间规整是必不可少的。DTW是一种将时间规整与距离测度有机结合的非线性规整技术,在语音识别时,需要把测试模板与参考模板进行实际比对和非线性伸缩,并依照某种距离测度选取距离最小的模板作为识别结果输出。动态时间规整技术的引入,将测试语音映射到标准语音时间轴上,使长短不等的两个信号最后通过时间轴弯折达到一样的时间长度,进而使得匹配差别最小,结合距离测度,得到测试语音与标准语音之间的距离。 2.支持向量机(SVM)支持向量机是建立在VC维理论和结构风险最小理论基础上的分类方法,它是根据有限样本信息在模型复杂度与学习能力之间寻求最佳折中。从理论上说,SVM就是一个简单的寻优过程,它解决了神经网络算法中局部极值的问题,得到的是全局最优解。SVM已经成功地应用到语音识别中,并表现出良好的识别性能。 3.矢量量化(VQ)矢量量化是一种广泛应用于语音和图像压缩编码等领域的重要信号压缩技术,思想来自香农的率-失真理论。其基本原理是把每帧特征矢量参数在多维空间中进行整体量化,在信息量损失较小的情况下对数据进行压缩。因此,它不仅可以减小数据存储,而且还能提高系统运行速度,保证语音编码质量和压缩效率,一般应用于小词汇量的孤立词语音识别系统。 4.隐马尔科夫模型(HMM)隐马尔科夫模型是一种统计模型,目前多应用于语音信号处理领域。在该模型中,马尔科夫(Markov)链中的一个状态是否转移到另一个状态取决于状态转移概率,而某一状态产生的观察值取决于状态生成概率。在进行语音识别时,HMM首先为每个识别单元建立发声模型,通过长时间训练得到状态转移概率矩阵和输出概率矩阵,在识别时根据状态转移过程中的最大概率进行判决。 5.高斯混合模型(GMM)高斯混合模型是单一高斯概率密度函数的延伸,GMM能够平滑地近似任意形状的密度分布。高斯混合模型种类有单高斯模型(Single Gaussian Model, SGM)和高斯混合模型(Gaussian Mixture Model, GMM)两类。类似于聚类,根据高斯概率密度函数(Probability Density Function, PDF)参数不同,每一个高斯模型可以看作一种类别,输入一个样本x,即可通过PDF计算其值,然后通过一个阈值来判断该样本是否属于高斯模型。很明显,SGM适合于仅有两类别问题的划分,而GMM由于具有多个模型,划分更为精细,适用于多类别的划分,可以应用于复杂对象建模。目前在语音识别领域,GMM需要和HMM一起构建完整的语音识别系统。 6.人工神经网络(ANN/BP)人工神经网络由20世纪80年代末提出,其本质是一个基于生物神经系统的自适应非线性动力学系统,它旨在充分模拟神经系统执行任务的方式。如同人的大脑一样,神经网络是由相互联系、相互影响各自行为的神经元构成,这些神经元也称为节点或处理单元。神经网络通过大量节点来模仿人类神经元活动,并将所有节点连接成信息处理系统,以此来反映人脑功能的基本特性。尽管ANN模拟和抽象人脑功能很精准,但它毕竟是人工神经网络,只是一种模拟生物感知特性的分布式并行处理模型。ANN的独特优点及其强大的分类能力和输入输出映射能力促成在许多领域被广泛应用,特别在语音识别、图像处理、指纹识别、计算机智能控制及专家系统等领域。但从当前语音识别系统来看,由于ANN对语音信号的时间动态特性描述不够充分,大部分采用ANN与传统识别算法相结合的系统。 7.深度神经网络/深信度网络-隐马尔科夫(DNN/DBN-HMM)当前诸如ANN,BP等多数分类的学习方法都是浅层结构算法,与深层算法相比存在局限。尤其当样本数据有限时,它们表征复杂函数的能力明显不足。深度学习可通过学习深层非线性网络结构,实现复杂函数逼近,表征输入数据分布式,并展现从少数样本集中学习本质特征的强大能力。在深度结构非凸目标代价函数中普遍存在的局部最小问题是训练效果不理想的主要根源。为了解决以上问题,提出基于深度神经网络(DNN) 的非监督贪心逐层训练算法,它利用空间相对关系减少参数数目以提高神经网络的训练性能。相比传统的基于GMM-HMM的语音识别系统,其最大的改变是采用深度神经网络替换GMM模型对语音的观察概率进行建模。最初主流的深度神经网络是最简单的前馈型深度神经网络(Feedforward Deep Neural Network,FDNN)。DNN相比GMM的优势在于:1. 使用DNN估计HMM的状态的后验概率分布不需要对语音数据分布进行假设;2. DNN的输入特征可以是多种特征的融合,包括离散或者连续的;3. DNN可以利用相邻的语音帧所包含的结构信息。基于DNN-HMM识别系统的模型如图2所示。 图2 基于深度神经网络的语音识别系统 8.循环神经网络(RNN)语音识别需要对波形进行加窗、分帧、提取特征等预处理。训练GMM时候,输入特征一般只能是单帧的信号,而对于DNN可以采用拼接帧作为输入,这些是DNN相比GMM可以获得很大性能提升的关键因素。然而,语音是一种各帧之间具有很强相关性的复杂时变信号,这种相关性主要体现在说话时的协同发音现象上,往往前后好几个字对我们正要说的字都有影响,也就是语音的各帧之间具有长时相关性。采用拼接帧的方式可以学到一定程度的上下文信息。但是由于DNN输入的窗长是固定的,学习到的是固定输入到输入的映射关系,从而导致DNN对于时序信息的长时相关性的建模是较弱的。 图3 DNN和RNN示意图 考虑到语音信号的长时相关性,一个自然而然的想法是选用具有更强长时建模能力的神经网络模型。于是,循环神经网络(Recurrent Neural Network,RNN)近年来逐渐替代传统的DNN成为主流的语音识别建模方案。如图3,相比前馈型神经网络DNN,循环神经网络在隐层上增加了一个反馈连接,也就是说,RNN隐层当前时刻的输入有一部分是前一时刻的隐层输出,这使得RNN可以通过循环反馈连接看到前面所有时刻的信息,这赋予了RNN记忆功能。这些特点使得RNN非常适合用于对时序信号的建模。 9.长短时记忆模块(LSTM)长短时记忆模块 (Long-Short Term Memory,LSTM) 的引入解决了传统简单RNN梯度消失等问题,使得RNN框架可以在语音识别领域实用化并获得了超越DNN的效果,目前已经使用在业界一些比较先进的语音系统中。除此之外,研究人员还在RNN的基础上做了进一步改进工作,如图4是当前语音识别中的主流RNN声学模型框架,主要包含两部分:深层双向RNN和序列短时分类(Connectionist Temporal Classification,CTC)输出层。其中双向RNN对当前语音帧进行判断时,不仅可以利用历史的语音信息,还可以利用未来的语音信息,从而进行更加准确的决策;CTC使得训练过程无需帧级别的标注,实现有效的“端对端”训练。 图4 基于RNN-CTC的主流语音识别系统框架 10.卷积神经网络(CNN)CNN早在2012年就被用于语音识别系统,并且一直以来都有很多研究人员积极投身于基于CNN的语音识别系统的研究,但始终没有大的突破。最主要的原因是他们没有突破传统前馈神经网络采用固定长度的帧拼接作为输入的思维定式,从而无法看到足够长的语音上下文信息。另外一个缺陷是他们只是将CNN视作一种特征提取器,因此所用的卷积层数很少,一般只有一到二层,这样的卷积网络表达能力十分有限。针对这些问题,提出了一种名为深度全序列卷积神经网络(Deep Fully Convolutional Neural Network,DFCNN)的语音识别框架,使用大量的卷积层直接对整句语音信号进行建模,更好地表达了语音的长时相关性。 DFCNN的结构如图5所示,它直接将一句语音转化成一张图像作为输入,即先对每帧语音进行傅里叶变换,再将时间和频率作为图像的两个维度,然后通过非常多的卷积层和池化(pooling)层的组合,对整句语音进行建模,输出单元直接与最终的识别结果比如音节或者汉字相对应。 图5 DFCNN示意图 识别技术的发展方向- 更有效的序列到序列直接转换的模型。序列到序列直接转换的模型目前来讲主要有两个方向,一是CTC模型;二是Attention 模型。
- 鸡尾酒会问题(远场识别)。这个问题在近场麦克风并不明显,这是因为人声的能量对比噪声非常大,而在远场识别系统上,信噪比下降得很厉害,所以这个问题就变得非常突出,成为了一个非常关键、比较难解决的问题。鸡尾酒会问题的主要困难在于标签置换(Label Permutation),目前较好的解决方案有二,一是深度聚类(Deep Clustering);二是置换不变训练(Permutation invariant Training)。
- 持续预测与自适应模型。能否建造一个持续做预测并自适应的系统。它需要的特点一个是能够非常快地做自适应并优化接下来的期望识别率。另一个是能发现频度高的规律并把这些变成模型默认的一部分,不需要再做训练。
- 前后端联合优化。前端注重音频质量提升,后端注重识别性能和效率提升。
参考文献:《解析深度学习:语音识别实践》-------俞栋,邓力著 《实用语音识别基础》-------王炳锡,屈丹, 彭煊著 《语音信号处理》--------赵力著
本内容部分原创,因作者才疏学浅,偶有纰漏,望不吝指出。本内容由灵声讯音频-语音算法实验室整理创作,转载和使用请与“灵声讯”联系,加qun方式:音频/识别/合成算法QQ群
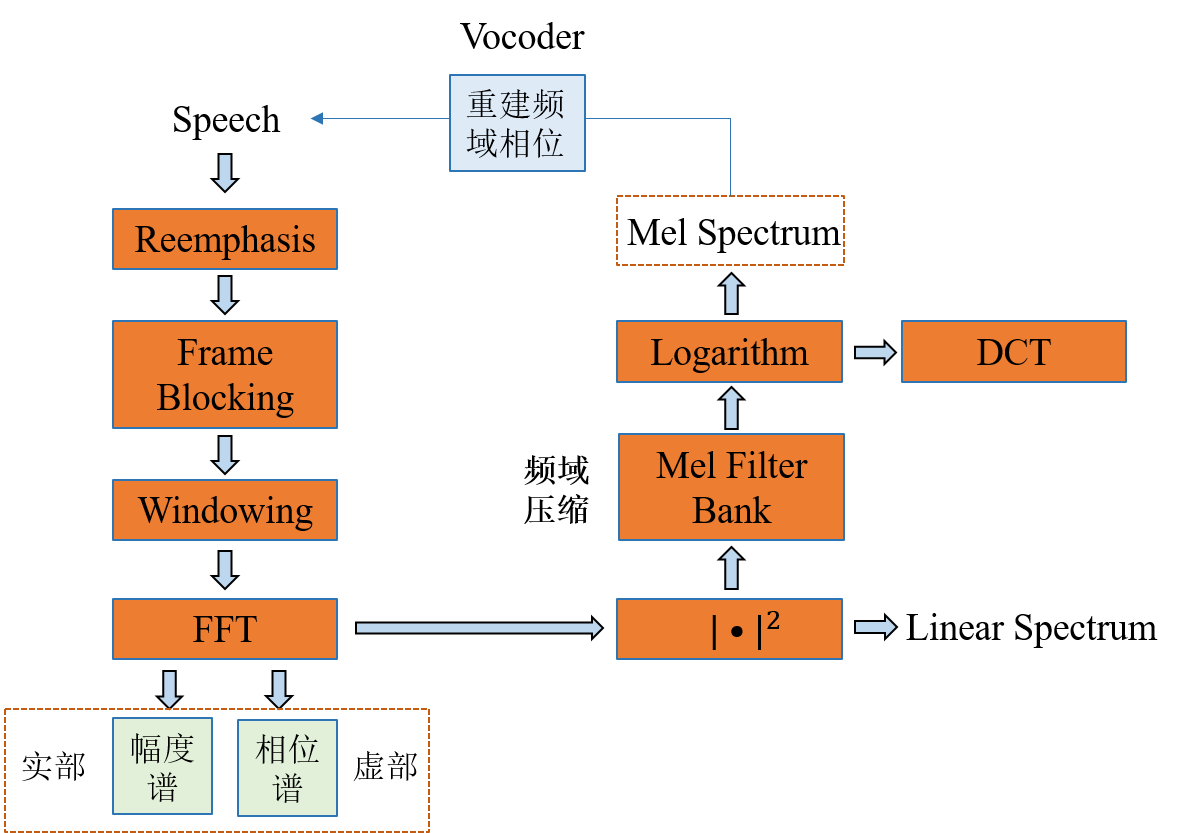
本文指在详细介绍语音转化声学特征的过程,并详细介绍不同声学特征在不同模型中的应用。 语音数据常被用于人工智能任务,但语音数据往往不能像图像任务那样直接输入到模型中训练,其在长时域上没有明显的特征变化,很难学习到语音数据的特征,加之语音的时域数据通常由16K采样率构成,即1秒16000个采样点,直接输入时域采样点训练数据量大且很难有训练出实际效果。因此语音任务通常是将语音数据转化为声学特征作为模型的输入或者输出。因此本文指在详细介绍语音转化声学特征的过程,并详细介绍不同声学特征在不同模型中的应用。 首先搞清语音是怎么产生的对于我们理解语音有很大帮助。人通过声道产生声音,声道的形状决定了发出怎样的声音。声道的形状包括舌头,牙齿等。如果可以准确的知道这个形状,那么我们就可以对产生的音素进行准确的描述。声道的形状通常由语音短时功率谱的包络中显示出来。那如何得到功率谱,或者在功率谱的基础上得到频谱包络,便是可以或得语音的特征。 一、时域图
图1:音频的时域图
时域图中,语音信号直接用它的时间波形表示出来,上图1是用Adobe Audition打开的音频的时域图,表示这段语音波形时量化精度是16bit,从图中可以得到各个音的起始位置,但很难看出更加有用的信息。但如果我们将其放大到100ms的场景下,可以得到下图2所示的图像。 图2:音频的短时时域图 从上图我们可以看出在短时的的时间维度上,语音时域波形是存在一定的周期的,不同的发音往往对应着不同的周期的变化,因此在短时域上我们可以将波形通过傅里叶变换转化为频域图,观察音频的周期特性,从而获取有用的音频特征。 短时傅里叶变换(STFT)是最经典的时频域分析方法。所谓短时傅里叶变换,顾名思义,是对短时的信号做傅里叶变化。由于语音波形只有在短时域上才呈现一定周期性,因此使用的短时傅里叶变换可以更为准确的观察语音在频域上的变化。傅里叶变化实现的示意图如下: 图3:傅里叶变换的从时域转化为频域的示意图 二、获取音频特征
由上述一可以知道获取音频的频域特征的具体方法原理,那如何操作将原始音频转化为模型训练的音频特征,其中任然需要很多辅助操作。具体流程如下图4所示:
图4:音频转化为音频特征的流程图
(1)预加重预加重处理其实是将语音信号通过一个高通滤波器: 其中\muμ ,我们通常取为0.97。预加重的目的是提升高频部分,使信号的频谱变得平坦,保持在低频到高频的整个频带中,能用同样的信噪比求频谱。同时,也是为了消除发生过程中声带和嘴唇的效应,来补偿语音信号受到发音系统所抑制的高频部分,也为了突出高频的共振峰。 pre_emphasis = 0.97emphasized_signal = np.append(original_signal[0], original_signal[1:] - pre_emphasis * original_signal[:-1])[/code](2)分帧由于傅里叶变换要求输入信号是平稳的,不平稳的信号做傅里叶变换是没有什么意义的。由上述我们可以知道语音在长时间上是不稳定的,在短时上稳定是有一定的周期性的,即语音在宏观上来看是不平稳的,你的嘴巴一动,信号的特征就变了。但是从微观上来看,在比较短的时间内,嘴巴动得是没有那么快的,语音信号就可以看成平稳的,就可以截取出来做傅里叶变换了,因此要进行分帧的操作,即截取短时的语音片段。 那么一帧有多长呢?帧长要满足两个条件: - 从宏观上看,它必须足够短来保证帧内信号是平稳的。前面说过,口型的变化是导致信号不平稳的原因,所以在一帧的期间内口型不能有明显变化,即一帧的长度应当小于一个音素的长度。正常语速下,音素的持续时间大约是 50~200 毫秒,所以帧长一般取为小于 50 毫秒。
- 从微观上来看,它又必须包括足够多的振动周期,因为傅里叶变换是要分析频率的,只有重复足够多次才能分析频率。语音的基频,男声在 100 赫兹左右,女声在 200 赫兹左右,换算成周期就是 10 ms和 5 ms。既然一帧要包含多个周期,所以一般取至少 20 毫秒。
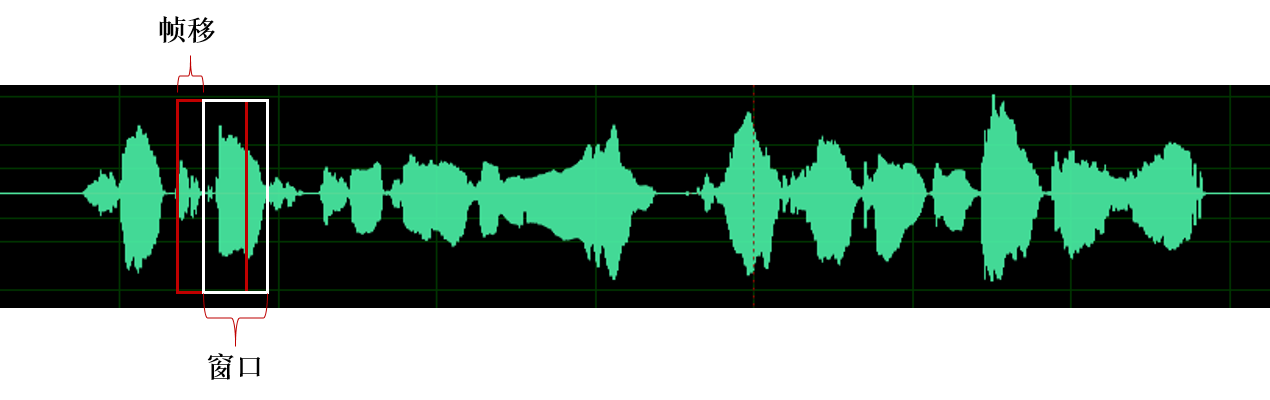
注意: 分帧的截取并不是严格的分片段,而是有一个帧移的概念,即确定好帧窗口的大小,每次按照帧移大小移动,截取短时音频片段,通常帧移的大小为5-10ms,窗口的大小通常为帧移的2-3倍即20-30ms。之所以设置帧移的方式主要是为了后续加窗的操作。
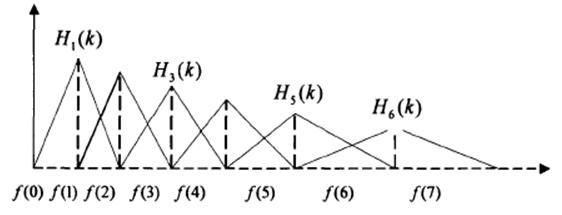
具体分帧的流程如下所示: 图5:音频分帧示意图 (3)加窗取出来的一帧信号,在做傅里叶变换之前,要先进行「加窗」的操作,即与一个「窗函数」相乘,如下图所示: 图5:音频加窗示意图 加窗的目的是让一帧信号的幅度在两端渐变到 0。渐变对傅里叶变换有好处,可以让频谱上的各个峰更细,不容易糊在一起(术语叫做减轻频谱泄漏),加窗的代价是一帧信号两端的部分被削弱了,没有像中央的部分那样得到重视。弥补的办法是,帧不要背靠背地截取,而是相互重叠一部分。相邻两帧的起始位置的时间差叫做帧移。 通常我们使用汉明窗进行加窗,将分帧后的每一帧乘以汉明窗,以增加帧左端和右端的连续性。假设分帧后的信号为 S(n), n=0,1,…,N-1, NS(n),n=0,1,…,N−1,N 为帧的大小,那么乘上汉明窗后: 实现的代码: # 简单的汉明窗构建N = 200x = np.arange(N)y = 0.54 * np.ones(N) - 0.46 * np.cos(2*np.pi*x/(N-1))# 加汉明窗frames *= np.hamming(frame_length)(4)快速傅里叶变换FFT由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布来观察,不同的能量分布,就能代表不同语音的特性。在乘上汉明窗后,每帧还必须再经过快速傅里叶变换以得到在频谱上的能量分布。对分帧加窗后的各帧信号进行快速傅里叶变换得到各帧的频谱。快速傅里叶变换的实现原理已经在前面介绍过,这里不过多介绍。详细的推理和实现推介参考知乎FFT( https://zhuanlan.zhihu.com/p/31584464) 注意 : 这里音频经过快速傅里叶变换返回的是复数,其中实部表示的频率的振幅,虚部表示的是频率的相位。 包含FFT函数的库有很多,简单列举几个: import librosaimport torchimport scipyx_stft = librosa.stft(wav, n_fft=fft_size, hop_length=hop_size,win_length=win_length)x_stft = torch.stft(wav, n_fft=fft_size, hop_length=hop_size, win_length=win_size)x_stft = scipy.fftpack.fft(wav)得到音频的振幅和相位谱,需要对频谱取模平方得到语音信号的功率谱,也就是语音合成上常说的线性频谱。 (5)Mel频谱人耳能听到的频率范围是20-20000Hz,但人耳对Hz这种标度单位并不是线性感知关系。例如如果我们适应了1000Hz的音调,如果把音调频率提高到2000Hz,我们的耳朵只能觉察到频率提高了一点点,根本察觉不到频率提高了一倍。因此可以将普通的频率标度转化为梅尔频率标度,使其更符合人们的听觉感知,这种映射关系如下式所示: 在计算机中,线性坐标到梅尔坐标的变换,通常使用带通滤波器来实现,一般常用的使用三角带通滤波器,使用三角带通滤波器有两个主要作用:对频谱进行平滑化,并消除谐波的作用,突显原先语音的共振峰。其中三角带通滤波器构造的示意图如下所示: 图6:三角带通滤波器构造示意图 这是非均等的三角带通滤波器构造示意图,因为人类对高频的能量感知较弱,因此低频的保存能量要明显大与高频。其中三角带通滤波器的构造代码如下: low_freq_mel = 0high_freq_mel = (2595 * numpy.log10(1 + (sample_rate / 2) / 700)) # Convert Hz to Melmel_points = numpy.linspace(low_freq_mel, high_freq_mel, nfilt + 2) # Equally spaced in Mel scalehz_points = (700 * (10**(mel_points / 2595) - 1)) # Convert Mel to Hzbin = numpy.floor((NFFT + 1) * hz_points / sample_rate)fbank = numpy.zeros((nfilt, int(numpy.floor(NFFT / 2 + 1))))for m in range(1, nfilt + 1): f_m_minus = int(bin[m - 1]) # left f_m = int(bin[m]) # center f_m_plus = int(bin[m + 1]) # right for k in range(f_m_minus, f_m): fbank[m - 1, k] = (k - bin[m - 1]) / (bin[m] - bin[m - 1]) for k in range(f_m, f_m_plus): fbank[m - 1, k] = (bin[m + 1] - k) / (bin[m + 1] - bin[m])filter_banks = numpy.dot(pow_frames, fbank.T)filter_banks = numpy.where(filter_banks == 0, numpy.finfo(float).eps, filter_banks) # Numerical Stabilityfilter_banks = 20 * numpy.log10(filter_banks) # dB然后只需将线性谱乘以三角带通滤波器,并取对数就能得到mel频谱。通常语音合成的任务的音频特征提取一般就到这,mel频谱作为音频特征基本满足了一些语音合成任务的需求。但在语音识别中还需要再做一次离散余弦变换(DCT变换),因为不同的Mel滤波器是有交集的,因此它们是相关的,我们可以用DCT变换去掉这些相关性可以提高识别的准确率,但在语音合成中需要保留这种相关性,所以只有识别中需要做DCT变换。其中DCT变换的原理详解可以参考知乎DCT( https://zhuanlan.zhihu.com/p/85299446) 本文分享自华为云社区《你真的懂语音特征背后的原理吗?》,作者: 白马过平川 。 想了解更多的AI技术干货,欢迎上华为云的AI专区,目前有AI编程Python等六大实战营供大家免费学习。 点击关注,第一时间了解华为云新鲜技术~
语音识别-语音助手-Speech Recognition -AI- 系统课程
手把手教你用JAVA实现“语音识别”功能(声音转文字)
什么是语音识别? 语音识别是指将自然语音转换为文本信息本篇文章将介绍“一句话识别”(对60秒以内的语音进行实时转写识别)
一、内容太长不愿意看,直接使用系列 首先确认接口调用要求: 时长限制:60秒以内 支持音频格式:wav,pcm 音频采样率:8000Hz,16000Hz 位深:16bits 声道:单声道 确认无误后,直接执行 2.2获取权限+2.3.3完整代码示例 什么是语音识别? 语音识别是指将自然语音转换为文本信息本篇文章将介绍“一句话识别”(对60秒以内的语音进行实时转写识别)
二、用JAVA调用标贝科技“语音识别”接口使用流程
2.1.环境准备 java
2.2.获取权限 2.2.1.登录 地址: https://ai.data-baker.com/#/index?source=gzh001 (注:填写邀请码hi25d7,每日免费调用量还可以翻倍)
点击上方地址登录,支持短信、密码、微信三种登录方式。
2.2.2.创建应用 登录后,点击创建应用,填写相关信息(未实名认证只能创建一个应用) (注:实名认证后可获得创建多个应用的权限)
进入应用,其中包含的技术产品有:语音识别、语音合成、声音复刻、声音转换
页面中功能主要包括:服务用量管理、购买服务量管理、开发者文档、授权管理、套餐管理
2.2.3.获取token 点击一句话识别—>授权管理—>显示—>获取APISecret—>(获取访问令牌token)
2.3.代码实现
2.3.1.获取token
/** * 授权:需要在开放平台获取【https://ai.data-baker.com/#/?source=qaz123】 */ private static final String clientId = "输入你的clientid"; private static final String clientSecret = "输入你的clientsecret"; /** * 获取token的地址信息 */ public static String tokenUrl = "https://openapi.data-baker.com/oauth/2.0/token?grant_type=client_credentials&client_secret=%s&client_id=%s"; public static String getAccessToken() { String accessToken = ""; OkHttpClient client = new OkHttpClient(); // request 默认是get请求 String url = String.format(tokenUrl, clientSecret, clientId); Request request = new Request.Builder().url(url).build(); JSONObject jsonObject; try { Response response = client.newCall(request).execute(); if (response.isSuccessful()) { // 解析 String resultJson = response.body().string(); jsonObject = JSON.parseObject(resultJson); accessToken = jsonObject.getString("access_token"); } } catch (Exception e) { e.printStackTrace(); } return accessToken; }2.3.2.httpclient发送post请求
public static void doSpeechRecognition(String accessToken, File audioFile, String audioFormat, Integer sampleRate) { try { OkHttpClient client = new OkHttpClient(); MediaType mediaType = MediaType.parse("application/octet-stream"); FileInputStream in = new FileInputStream(audioFile); byte[] fileByte = new byte[(int) audioFile.length()]; int realLen = in.read(fileByte); //确保音频文件内容全部被读取 if (realLen == (int) audioFile.length()) { RequestBody body = RequestBody.create(mediaType, fileByte); //构造request Request request = new Request.Builder() .url(asrUrl) .addHeader("access_token", accessToken) .addHeader("audio_format", audioFormat) .addHeader("sample_rate", String.valueOf(sampleRate)) .addHeader("domain", "common") .method("POST", body) .build(); Response response = client.newCall(request).execute(); if (response.isSuccessful()) { JSONObject jsonObject = JSON.parseObject(response.body().string()); System.out.println("识别成功,识别结果:" + (jsonObject == null ? "" : jsonObject.getString("text"))); } else { System.out.println("识别失败,错误信息:" + response.body().string()); } } } catch (Exception e) { e.printStackTrace(); } }2.3.3.完整代码示例 package ......import com.alibaba.fastjson.JSON;import com.alibaba.fastjson.JSONObject;import okhttp3.*;import org.apache.commons.lang3.StringUtils;import java.io.File;import java.io.FileInputStream;/** * (一句话)在线识别RESTFUL API接口调用示例 * 附:在线识别RESTFUL API文档 【https://www.data-baker.com/specs/file/asr_word_api_restful】 * * 注意:仅作为demo示例,失败重试、token过期重新获取、日志打印等优化工作需要开发者自行完成 * * @author data-baker */public class AsrRestApiDemo { /** * 授权:需要在开放平台获取【https://ai.data-baker.com/】 */ private static final String clientId = "YOUR_CLIENT_ID"; private static final String clientSecret = "YOUR_CLIENT_SECRET"; /** * 获取token的地址信息 */ public static String tokenUrl = "https://openapi.data-baker.com/oauth/2.0/token?grant_type=client_credentials&client_secret=%s&client_id=%s"; /** * 一句话识别API地址 */ public static String asrUrl = "https://openapi.data-baker.com/asr/api"; /** * 音频文件 */ public static String audioPath = "/home/asr/16bit_16k.pcm"; /** * 文件大小限制:开发者需注意服务端会校验音频时长不超过60S。demo作为示例,简化为只校验文件大小 * * @param args */ public static Integer MAX_FILE_SIZE = 10 * 1024 * 1024; public static void main(String[] args) { String accessToken = getAccessToken(); if (StringUtils.isNotEmpty(accessToken)) { File audioFile = new File(audioPath); //一句话在线识别支持的音频长度在60S内,开发者需注意音频流的大小 if (audioFile.exists() && audioFile.length() < MAX_FILE_SIZE) { //支持pcm和wav格式:如果是wav格式,audioFormat设置为"wav";如果是pcm格式,audioFormat设置为"pcm" doSpeechRecognition(accessToken, audioFile, "pcm", 16000); } } } public static void doSpeechRecognition(String accessToken, File audioFile, String audioFormat, Integer sampleRate) { try { OkHttpClient client = new OkHttpClient(); MediaType mediaType = MediaType.parse("application/octet-stream"); FileInputStream in = new FileInputStream(audioFile); byte[] fileByte = new byte[(int) audioFile.length()]; int realLen = in.read(fileByte); //确保音频文件内容全部被读取 if (realLen == (int) audioFile.length()) { RequestBody body = RequestBody.create(mediaType, fileByte); //构造request Request request = new Request.Builder() .url(asrUrl) .addHeader("access_token", accessToken) .addHeader("audio_format", audioFormat) .addHeader("sample_rate", String.valueOf(sampleRate)) .addHeader("domain", "common") .method("POST", body) .build(); Response response = client.newCall(request).execute(); if (response.isSuccessful()) { JSONObject jsonObject = JSON.parseObject(response.body().string()); System.out.println("识别成功,识别结果:" + (jsonObject == null ? "" : jsonObject.getString("text"))); } else { System.out.println("识别失败,错误信息:" + response.body().string()); } } } catch (Exception e) { e.printStackTrace(); } } public static String getAccessToken() { String accessToken = ""; OkHttpClient client = new OkHttpClient(); //request 默认是get请求 String url = String.format(tokenUrl, clientSecret, clientId); Request request = new Request.Builder().url(url).build(); JSONObject jsonObject; try { Response response = client.newCall(request).execute(); if (response.isSuccessful()) { //解析 String resultJson = response.body().string(); jsonObject = JSON.parseObject(resultJson); accessToken = jsonObject.getString("access_token"); } } catch (Exception e) { e.printStackTrace(); } return accessToken; }}
标贝开放平台地址:(点击阅读原文直接跳转) https://ai.data-baker.com/#/index?source=gzh001 (注:填写邀请码hi25d7,每日免费调用量还可以翻倍)
———————————————— 版权声明:本文为CSDN博主「DataBaker」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
语音识别,本质上还是图像识别。简单来说,机器把声音变成图片(声音频谱图),然后使用深度学习,对它进行识别(和对应的文本匹配)。
语音识别的本质是一种基于语音特征参数的模式识别,即通过学习,系统能够把输入的语音按一定模式进行分类,进而依据判定准则找出最佳匹配结果。目前,模式匹配原理已经被应用于大多数语音识别系统中。 一般的模式识别包括预处理,特征提取,模式匹配等基本模块。首先对输入语音进行预处理,其中预处理包括分帧,加窗,预加重等。其次是特征提取,因此选择合适的特征参数尤为重要。常用的特征参数包括:基音周期,共振峰,短时平均能量或幅度,线性预测系数(LPC),感知加权预测系数(PLP),短时平均过零率,线性预测倒谱系数(LPCC),自相关函数,梅尔倒谱系数(MFCC),小波变换系数,经验模态分解系数(EMD),伽马通滤波器系数(GFCC)等。在进行实际识别时,要对测试语音按训练过程产生模板,最后根据失真判决准则进行识别。常用的失真判决准则有欧式距离,协方差矩阵与贝叶斯距离等。
来源:知乎 |